This is the second part of the eShopSupport Series which covers the details of the eShopSupport GitHub repository.
DataIngestor Project
The DataIngestor is a console application that will process the data files created by the DataGenerator - it does not ingest the data into any of the databases. I mentioned in the last entry about the DataGenerator that you didn’t need to use the DataGenerator because there are two sets of generated files provided in the github repo: dev and test. What I failed to mention is those files are result of both the DataGenerator and the DataIngestor being run. So you also don’t have to use the DataIngestor.
The DataIngestor project is located under the src folder:
In this entry I’ll cover the details of what the DataIngestor application does, a few interesting things I found interesting and some thoughts on improvements.
What does it do?
Steve Sanderson mentions this project around 21 minutes into his NDC talk “How to add genuinely useful AI to your webapp (not just chatbots)”, with the subheading of “Parsing, Chunking, Embedding” … which pretty much sums up what this project does. It takes the files the DataGenerator project created and processes them into a format that can be used to seed the databases.
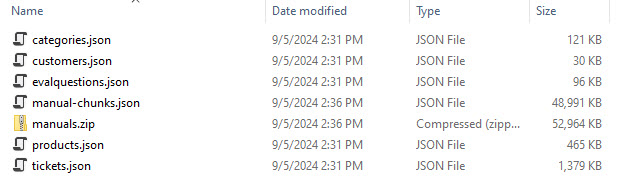
The purpose is to generate files that will be used by the applications to bootstrap their data when they start up. This may or may not be how you would do it for a production system, but it really makes open source demo projects more accessible to a wider experience level to easily get the application up and running with sample data. Here are the files it will create from the files the DataGenerator created:
NOTE: I will cover the population of the databases and processing of the manuals in a future blog entry, since it is done in the Backend project.
Like the DataGenerator, all the important logic is driven from the Program.cs file:
await new TicketIngestor().RunAsync(generatedDataPath, outputDir);
await new ProductCategoryIngestor().RunAsync(generatedDataPath, outputDir);
await new ProductIngestor().RunAsync(generatedDataPath, outputDir);
await new EvalQuestionIngestor().RunAsync(generatedDataPath, outputDir);
await new ManualIngestor().RunAsync(generatedDataPath, outputDir);
await new ManualZipIngestor().RunAsync(generatedDataPath, outputDir);
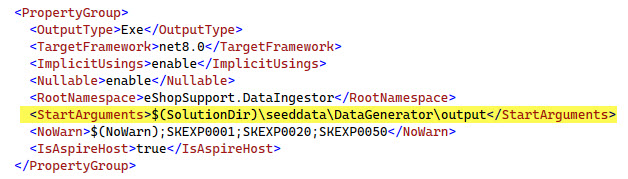
If you run the project from Visual Studio, it will look for the files to process in the location the DataGenerator writes it’s files:
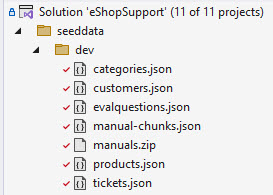
It will output it’s files to the \seeddata\dev directory, overwriting any files that were already there:
Tickets and Customers
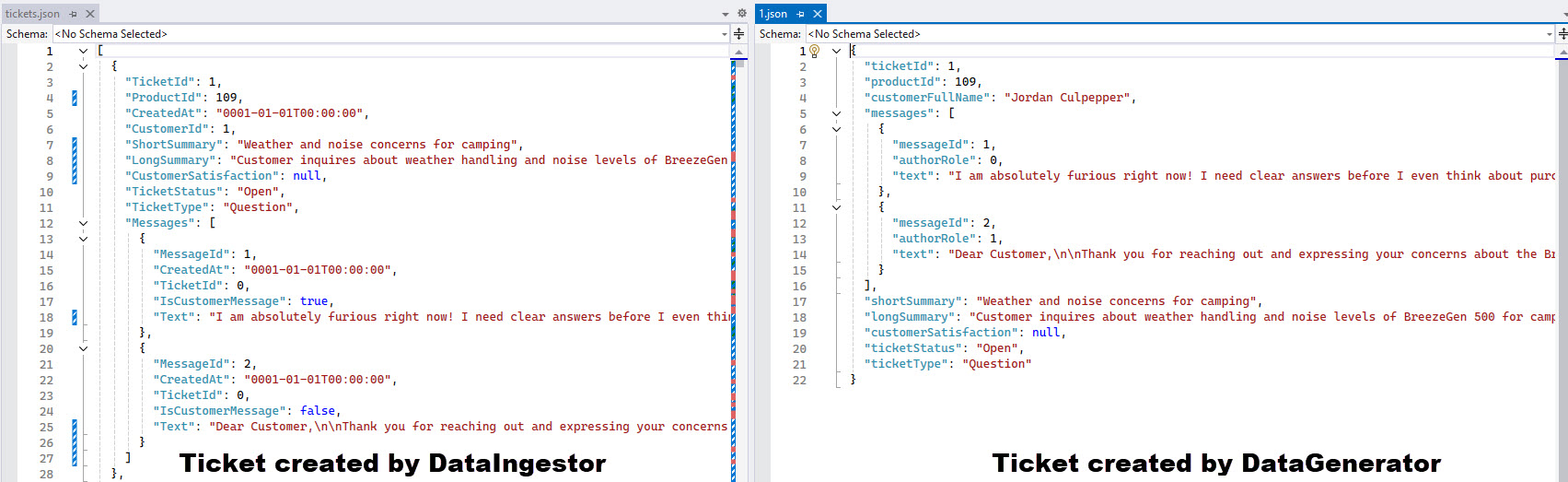
The TicketIngestor reads in all the files in the /output/tickets/threads directory (more information on these files), loops through them creating two things:
- a unique list of customer names
- a new Ticket data object that better matches the object to be saved to the database
Once all ticket threads are processed, there are two files created:
tickets.json - a json file containing the new Ticket object format and aggregates all generated tickets and their message threads:
customers.json - a json file containing a unique listing of all the customers in all the tickets generated by the DataGenerator:
[
{
"CustomerId": 227,
"FullName": "Trevor McAlister"
},
{
"CustomerId": 414,
"FullName": "Morgan J. Blackwell"
},
{
"CustomerId": 313,
"FullName": "Jordan Mallow"
},
{
"CustomerId": 128,
"FullName": "Jordan W. Mallory"
},
{
"CustomerId": 353,
"FullName": "Jacqueline Marsden"
},
// ...
}
Categories
The ProductCategoryIngestor reads in all the files in the /output/categories directory (more information on these files). Like with tickets above, the ProductCategoryIngestor maps the generated category to a new ProductCategory object that will be saved in the database later. Plus an embedding is generated for the category name using the LocalTextEmbeddingGenerationService:
foreach (var filename in Directory.GetFiles(categoriesSourceDir, "*.json"))
{
var generated = (await JsonSerializer.DeserializeAsync<GeneratedCategory>(File.OpenRead(filename), inputOptions))!;
categories.Add(new ProductCategory
{
CategoryId = generated.CategoryId,
Name = generated.Name,
NameEmbeddingBase64 = ToBase64(await embeddingGenerator.GenerateEmbeddingAsync(generated.Name)),
});
}
Once all the categories have been processed and the embeddings retrieved, they are saved in a single categories.json file, which looks like this:
[
{
"CategoryId": 1,
"Name": "Solar-Powered Backpacks",
"NameEmbeddingBase64": "lR0wwGDRJ0ByLpI/ajImPgNisT92MQc/ody9P0EDg78Yfte\u002BLasLQPoHtT/9l0jAUBeavz7JeECqRV1AUKI/vszNMUDeqTRAx3G5vsHDtz\u002Bt4I1AmloewPOaDMDWIcC/Va9Kv56tML4hYw8/afWAv8pSNMCahMXAbGI\u002BP7ojY8Bayg/ABG7ev22iZb\u002BGt\u002BQ9/SCTPz3AD8A7pBzAm9erP/Jz/76C5gC/MvjSvwTWEz8njaa//Qe8vwyiTD5k8EPAY/rnP/WgNcAzL4g/AK0UwPWIqL6pqNW9Ss\u002Bjvysbqz\u002BKPwo/H/pCQMbzGkAYE\u002B293NgAQPQNwz/\u002BuPzAKZwVQJwjR0CUnGo9ZYUNwN\u002B/qz\u002BStyBA\u002BK3gPlCzsj6ep4c\u002BwEOuO1t0BEAb/zA/KK8EQFqzs7/Qgp6/dVSovxuIAsAxjfa/tf2KvhhOkL4iVTtATu72PzGye0DaPMW\u002B8BI2vn6yCkDJNJo/4Nnzv8x0gL\u002BClJS\u002BcsZFQPCAwcDSAcK/UV\u002BzP2chbL6VJOU/6F4EQcxBlb/1LmpAXWu6QIgF472yA7k\u002BfZeBwCHY1z8u5q\u002B/EL41v/QitD1XN\u002Bs97rE7PdQAI78Kqh0\u002BtU0BQP\u002BRy7\u002BFAxvA/xO7P4zZbcDTkoRAHHCIwOrN/D57ea1AVhu\u002Bvv7ypD8CtvA\u002BzFl3QA/RE0D3RYO\u002BxPp7QMAiFz9mBsc/LDgwvySGB8BzRCC/0Eh4P9wFDL7fSSfAFHOTP8SzID\u002Bu0dY/PnhlQFTdDEDAoebAkGg7PBPnlb9Y08o9O8\u002BwP7hWE8CLJ/Q\u002B5l9KP5/CDEArwjxASRzIv18L9z8ESVxArTNOv5leVz6yuTw\u002BFChhPzwp7L5M7/4/b\u002BSsv1QbCUA9lgU/bnSGwMA54ryYIdY8aUOSP4IvmD/CocQ/qXEvQFqOHkBCu1S/CP\u002BqQOYjz78p0qfADg6Uv2w1R8CRLnk/xpKDPxnZID97HiA/VvgDwI7x4D8ij6496I/Qv4cbCr/0ujo/jqJPQPSRPsCI\u002BV6/\u002B7QgQNFNUz\u002BsM4s\u002BGpqGPrKl/b88h2fAJgo3P2JA5r8FmFpAa2Gpv3Fj27\u002B0JllA/TvzP7HdwL7/sKi/IJUKvma2vL/osD48w4LYPy4O6r94Uq0\u002BEpzHvaHOpcCC3Gk/yHFvP5g1Rz1igV6\u002B3pyGPsCOyTvPR7vAFc6KwHbMKMFYUD0/ozwyPx/jhz\u002BEWdW9BKnBPUYEPUA2v5K/8B/\u002Bv9Zsb78aUrFALFpLwNhaCD\u002B7cmk/XxawvtbVDUCf1d8/Ak8wwBjYmL/yaKa/YHhcv7HG4T/ZxCJA/hbvv/bGNz8cEfa/zrzjQPbIFEBZKipArHaovnCWOr/0tko/gcPBP4HumMAXfOs/xY0oQCxvRj0w7fu/FYWNPkn0pr\u002B0y66\u002BOL6vQM7EB8Ck3iPA9LcMPzyKHj/Xlt\u002B/xKWcv/jSjj65/grAD4igvok8gb/871E\u002BRzFnwKqnK0CBZg2/ZObkv2MbS0A6H9S/nj/TPxvz/79jq4W/khYcwLfKlD2WyxI/U3FrPt6FVb\u002Bjb/K\u002BuZYCP1TL274qSgi/tk2aQOx1jj/XcJY/ZW0nQAc5gL\u002BTbA1AQgjePwyVVECwe\u002Ba/jrOHvlsoIEB/mpO/DkCiv1T0qD8iVKk/\u002BrIbwMS32r/MEta/TE/8vxtjcD7wYtE/Di8RwIyOHr863spATGntvJGmL8HSGAA/xC4WvxG0FcAMujzAG1QXP0TvLkA7OXlAH/bJP5ZnqD9ECtK/S2MPQEhRKL6qsxE\u002B1/FKQEL0r74JNUBAg/dTv9GHPz91GR7AFlndP38HHj8sUNhAY2ASv\u002By9/75OlU5AJ6j\u002BvyEtnj8PNh0/kIqDvugjlr7vLI093HI5QGqBAb8nVW6/YAAqQMYGM79n1THANBp4Pyg/lr8NVwo\u002BvH5uP9l5jsAIEnu\u002B0Xy8P3ESMcCcTJC945\u002BowJiyWD1Sj\u002B6/DTM2v9nUTD7NoTrASNrdPo\u002B5E75ixku\u002Bqj9tv45PBcC0\u002BqO/ZFXEv2h8B0CorxG/LBvsvvNeCsDkkcO\u002B"
},
//...
]
NOTE: the brands that were in the generated files are not carried over to the category.json file.
Products
The ProductIngestor reads in all the files in the /output/products directory (more information on these files). As it loops through each of the generated products it maps the information to the Product object and retrieves an embedding for the concatenated string $"{generated.Model}, {generated.Brand}". The code looks almost the same as the ProductCategoryIngestor except for the NameEmbedding being ReadOnlyMemory<float> versus the NameEmbeddingBase64 being a string in the ProductCategory.
foreach (var filename in Directory.GetFiles(productsSourceDir, "*.json"))
{
var generated = (await JsonSerializer.DeserializeAsync<GeneratedProduct>(File.OpenRead(filename), inputOptions))!;
products.Add(new Product
{
ProductId = generated.ProductId,
CategoryId = generated.CategoryId,
Brand = generated.Brand,
Model = generated.Model,
Description = generated.Description,
Price = generated.Price,
NameEmbedding = await embeddingGenerator.GenerateEmbeddingAsync($"{generated.Model}, {generated.Brand}"),
});
}
When you look at the products.json file, you will see the NameEmbedding is saved in the json file as a Base64 encoded string, even though it was not converted to a strind like in the ProductCategoryIngestor:
[
{
"ProductId": 1,
"CategoryId": 43,
"Brand": "CoolCampers",
"Model": "ThermoTent Pro 3000",
"Description": "Experience ultimate comfort with our climate-controlled tent featuring advanced thermal regulation tech. Perfect for any camping season.",
"Price": 499.99,
"NameEmbedding": "IBUxwI9cjkAHCKZA1co1wFSCXz8bFzhAycxjwA0o1T5Gg/K/b8Lgv24PNEBoHTzA7v8+QADo0bhjX7c/+dc7QKkv5j9qgTBAtHlOQAMPwT9dNjxAf1DIwC8LWz6Nk/G/2AFbvwjOJUCuAZXArACTv5Y0R8BONETBYVGiP1Wct8CoWbxAmm8EwGKB8b9lokDAVCHev8+YHUBekXrAzbx0v9zf0L8BbzFAthaewF8N1j0j10A/3ygWv7h3x7/nahTAiNzkvU0u178srue+SpwGwIwU676W50e++g4QQK5bE0Aykl5AVcBHP2AawL7cnhFAZdEMQHvakUDEcynB7KWdQFurkz+nTsy+NvquwAZKnb8QGrO+eE9Nv8XhBsA+jCFARb82QHdvnz8Qeo6/mXiTvxNVP8BJhULAnFzAv3tRDT9yXynABL0OwP7pXL9kzQrA/nFbP3SOhcDJVoBAypcTwBolk0AQQ+W/Jd+twJ1nnT1dhTvAjSksPzBY5r9sP8e/Qi2FQKTsrL6xrHJAbPwVQQh1Hr6J/GJA1U+TQBbdEcAgS1E/Hw6GwL6PT0DlIsG/o379wNoMaj/ryto/DhEtvw/B0z4ivyDAFF3tP61UJcBwEc4//JkIQIGqlr5HuZBAzLbqv8A6gj8uE6xAPAxVwGQgo7/gT4G+FDyaPt18lkBcfVFAZv3fQAC0FUBlMARB20gzv8dOhT8ItIQ/mdMUwMZuO0BwdkLAixOEQDbWC0CK4+++CqiuQHCuhEBeE0nBhhHnviiZ/j5ncy6+h0mXQFVkFMCiMShAL/cUwKwXW0B8VUlAawMLwKWZeEDT8FxAzyk0QC+lP0CvTcDA5xgKQFeeKD++B0jAHpFlQHe5WkCCa1pAFRwCwasxuEDwNRNAylWlv7e/pL+iR4W/QNC7vkMThsA/3pS/Pn6aQIJ55D/dtZvAeyLfv8KfA0BIYDNAmzz1PrVCI8De1fY/0FZGv7eFY0AcgJnAwIzDv3ryN8A8aE8/G5/SQNWsgT/IIyS/fKsyvV6Bmj4Abmg6ad8pQOrPH8DH57u/1ZUZQFtGxMBbDYxASyqyvx5gM8CmeCdAvFKGQBOaE0DW7te/AoUDwMUJFkAE6eM/fTjIP5T7EsD+fZtAdYLGPtrGH8DCgTe/oMi/vt4Umz3Ig4TAGlXBvwxULUCQ4JPApgoBwQMZisHss4q+TG2jPgw9AsB9J8ZA1iBGQIC1Oj0ux3i/cNbpP6K4w74+UgZBF/nJv9hVFz7z7cC/UbaAwL61NED6Zgq/eMLdvi48Nj84giy+yDW3vpruVEBOk/u/QvQCwEMy2b99xonA8bROQUBaVkAffBVAPKaLv6ARkUAWEq0+B2a5v1+5I8G69ytA/BouvxBFg0BSWkO+3OukPY5XqMBlOIs/OMEIQX6UWr6KkPbA5uSvvy21UcDbdiW/HC66v2ShBcAmhy5APw9gP5RZ/T+C9iI/FLoYwImiKECRvUTAsgn4wIG7zD8LIyHAXbHDQNKbcz897TfAzyY1P6dUND/bb48/4I5IQDtoLz/rFhrAxme2QO4XwMBrKgxAqeKTQKUUWT8pXky+KNF7QCHhjb+XnZ5AUiCmv9G7GED0Kn4/oH/cvjhIMkAlGby/E7/dv1zdI0Cm4CxAWDRYwMse27/VkoVAtFk7PsfUCT/TN6pAunAYwOjNZT+hnVlAKD6yP83losFaP+E/ReKQP3Jfsr/y4Wg+66qnwP38BsAB4q09IeZ4v6IOsT/SE+a/7LWcP+gYkT2JOBxA7CesP8Tx1L/XOjJA6lcSwNWtnUC+1IjAFfdVv/4Mwz/zeXJBqf/wvyk+PMB/Bfg/qoVAvQRp5T9+/VZA/I53PjE7hr+tP2/A/k3JP4dnfj6bJRI+b4fLQHoWoT52kXq/vD/vPTc22T+397+/LE0UwDb+iT6GgTm/+Q3wQLi1FsAWmp6/2VRtwI9hbsC8nGg/WarWvuZBoMB23Ku/NDmhPvDl97/NfFNAZb+JvyzSrcCWIGzAiXPFwMN0lL+J0qk/C4GJQLOGhj8EFglA"
},
//...
]
This Base64 string conversion is done using the JsonConverter attribute on the property:

The code for the EmbeddingJsonConverter, looks like a useful utility to keep in mind:
class EmbeddingJsonConverter : JsonConverter<ReadOnlyMemory<float>>
{
public override ReadOnlyMemory<float> Read(ref Utf8JsonReader reader, Type typeToConvert, JsonSerializerOptions options)
{
if (reader.TokenType == JsonTokenType.Null)
{
return null;
}
if (reader.TokenType != JsonTokenType.String)
{
throw new InvalidOperationException($"JSON deserialization failed because the value type was {reader.TokenType} but should be {JsonTokenType.String}");
}
var bytes = reader.GetBytesFromBase64();
var floats = MemoryMarshal.Cast<byte, float>(bytes);
return floats.ToArray(); // TODO: Can we avoid copying? The memory is already in the right format.
}
public override void Write(Utf8JsonWriter writer, ReadOnlyMemory<float> value, JsonSerializerOptions options)
{
var bytes = MemoryMarshal.AsBytes(value.Span);
writer.WriteBase64StringValue(bytes);
}
}
EvalQuestions
The EvalQuestionIngestor reads all the files in the /output/evalquestions directory (more information on these files). As it loops through each of the generated files it deserializes them into a EvalQuestion object (notice it is in the Evaluator project not the Backend project like the others). Once all items have been deserialized, a new evalquestions.json file is created with all the evalquestions. Unlike the other json files created so far, these are not going to be objects stored in a database later - instead they are going to be used by the Evaluator project.
The end file looks like this:
[
{
"QuestionId": 1,
"ProductId": 44,
"Question": "can I use underwater?",
"Answer": "Not waterproof."
},
//...
]
Manuals
There are two steps for processing manuals: ManualIngestor and ManualZipIngestor.
The ManualIngestor processes all the pdf files from the /output/manuals/pdf directory. The processing steps for each pdf are as follows:
- Open the Pdf document
- Get all the pages
- Chunk the pages into paragraphs around 200 tokens in length
- Get the embeddings for the paragraph chunks
- Create the object
The End result is a list of ManualChunk objects. These will end up in a vector db eventually.
NOTE: the embedding property on this object is a
byte[]which the JsonSerializer will marshal as a base 64 string.
// Loop over each page in it
using var pdf = PdfDocument.Open(file);
foreach (var page in pdf.GetPages())
{
// [1] Parse (PDF page -> string)
var pageText = GetPageText(page);
// [2] Chunk (split into shorter strings on natural boundaries)
var paragraphs = TextChunker.SplitPlainTextParagraphs([pageText], 200);
// [3] Embed (map into semantic space)
var paragraphsWithEmbeddings = paragraphs.Zip(await embeddingGenerator.GenerateEmbeddingsAsync(paragraphs));
// [4] Save
chunks.AddRange(paragraphsWithEmbeddings.Select(p => new ManualChunk
{
ProductId = docId,
PageNumber = page.Number,
ChunkId = ++paragraphIndex,
Text = p.First,
Embedding = MemoryMarshal.AsBytes(p.Second.Span).ToArray()
}));
}
The end file looks like this:
[
{
"ChunkId": 1,
"ProductId": 1,
"PageNumber": 1,
"Text": "ThermoTent Pro 3000 (c) CoolCampers 1",
"Embedding": "lUSUwHvayUC6jt1AQ/llwNSMIb50PkhANbOIwAhzNj/9KRe/Y4Srv9RgVEB6moPA7fZeQFZ7CT/UZHI/yUVYQH5E8z8czB5AEFauQFhqFUDPujtAeWEEwUTVCr3BWDrAssSjv+kGIECBr7TALIcNwEgPH8AQ4H/BCVIGQH/X3sDSNQFB+KkFwNRgOsDOA4rARYEQwCkvL0BYJKrAKq6tvoq5279x1B9Ak2qvwOBzkb4UNtq+j5DSvXUnhr/itdu/Yh9ePxMj37+xddC+o7sCwGqHU78tlo6/Qj5MQGS1mD/I6ZNAfdoKQFhaqL5owxFAMn0WQE/hg0C9glTBLn+8QIhtyT+sDMC+GpmswIAWUcB9syw/sowjQOLTYMAx8wZA4YZZQCDrsjuz2De/oS04wOEAdsAH/SnAdotZv4lZhj8tarHAIP42wIH2McBnCR3ARJ9OP870u8AYjohAbQE+wNxZsEDMgS/AikCswIjHCb9gR4bA+EiGP6RNecDTC4K/1PShQDdzLz/oRqFAOtM6QeJS/D0wgAhAjRiIQAvcD8ChrfU/WPmfwPlMi0DUGh3AY24JwcnGMz9sUz1AIimMv8pdBT6fAHPAYHQTQFJ2OMDf1SFAw409QFiQWT9fQLpA7d0qv+ohnD7y5uxA8LCKwAoxFMCMTSs/zDQcP+Erp0AwRlZANg4HQaz1c0ALFg5B35DZPkm2yT9tssE/jpvFv2y0M0AI42u/bmx+QPQf6j9A6Bo7sHncQJiCv0DKhWDBBCdkPqKNOL7Fl2g/YBqKQDIZVMDXa14/8hoewE0liUDwaZBAqUEywN7bjEAm/HJAacoOQB7VGkAMweHAF+wjP+pOpz/6/5PAy7pnQJyFmUChD6xAMJYhwZTL+EAkazZAoFX5v5rZDr8Fq/S/wAQeu8yAiMCafu+/QA6lQLpfH0BmRtbATWs9wIgsRUA0AopAuCN9PzfzMMBMyjNAVA4+v785okAixsjA2fIJwOTxU8A4980/Xv0VQRj2jzwb6e+/vOqqPpLzhj8v1nY/qwBYQB87YMCcOuy/muvjP+IS48AWeQ9BxmCbv1JlOMC0VmhA2ox6QFuF8z/2cby/6G8swN/sEkDwtAJAT5m8P2KnHsDyJaxAOLzKvnPUDcDhRS6/0JemPtuWCz980ErADtGcvwWXxj9n+63At9UdwQiVr8E07AO/7ESUP24TJcCG8/FA+kxZQDNOkz+MTkC/fwDLPz4rOcAscxJBU2riv4RHqr+I3wvA0gqwwHsIWEBA4Fi/ki+SvpGypT/kxMm+ZWuVP+Rze0C6xEvAAJ6Bv1Q4EsBrgrnAzFx5QdDGwz/3wVxACP9QvUwrrkDK09+9O0AawKpAJsEUwbQ/2KaDvRlUOUDOsA6+FGzVPpPOpMDEmElApcYXQezbwr+lAQXBYR4kwDvTfsDItMW/yWeYv3xG4L9FCHFA5Vgkv3qCfT/Esxm+VxCgv0phMkDk9pvAZdEXwYoPzD9DWhHAfynYQBK/BT+nLW7AbBXJP49MMD9wSfA/P6xCQO3hhT/Z8lzACNXbQEaE2sCW5kZAOMjWQCahnz+QtBQ+Dh2VQDrBlr/qz9FAJslmvx2S/z/YUw8/cVbWvy9LbkAbqgXAQpvfv+RKHEBN4FtAZRc+wCBy4L5u0KJAP+rEvnLzbD+HQLhAxt7dv9nnHUCgOXlAzp3kP7xUxcEA9Jk/CPT6PqThoL+isaI+4am2wG1dBMDaZV++cjcswBbrFEBxP2nA5t4aQIupmj+rM5lAgGzcPpRIdMDeTWtAMtFewCCrokB/VqLA7BPZPiKflj+flYtB3PcBwHY8SsA7fh1AoBrlO2/YAUBQb5RA4uVevmmyEMBp02/AK5kCQFa3Wr0wbE4/8KcLQUyuQz8plt6/SNOBPdpfakCfz9y/RwjQvx44Rz0eZLa/Za8eQYN5OsDe9R/AOZW5wHpLoMDp1gC/URUbwC0ckcBaXOK+E+DmvpZhC8Ch6ZZAWSQVwDGZlcCwpK3A5uPVwDaRX7+lBQNA5LPaQH5SLD9sPotA"
},
// ...
]
The ManualZipIngestor creates a zip file of all the files in the /output/manuals/pdf. The pdfs in this zip file will eventually be put into blob storage.
Dependencies
The DataIngestor project uses a few dependencies to provide functionality with the file generation:
- PdfPig - used to work with Pdf files.
- SmartComponents.LocalEmbeddings.SemanticKernel - used to retrieve embeddings for names and chunks of the manual text. This uses the Onnx runtime behind the scene with the model.onnx and vocab.txt file you can find in the LocalEmbeddingsModel directory after you build the project.

How to set it up
In order to successfully run the DataIngestor, you need to first run the DataGenerator (more on getting the DataGenerator setup) in order to have the output directory files.
The DataInjestor only needs a path to the generated files to run. If you run it in Visual Studio the default is set for you in the csproj file:
<StartArguments>$(SolutionDir)\seeddata\DataGenerator\output</StartArguments>
Points of Interest
These are some points in the code base that I found interesting and will be revisiting when writing my own code.
Usage of local embeddings
There are three usages of the LocalTextEmbeddingGenerationService in this project: ProductCategoryIngestor, ProductIngestor and ManualIngestor - all shown above. Another interesting note is they each map to different property types:
ProductCategory has a string NameEmbeddingBase64 property:
public class ProductCategory
{
...
public required string NameEmbeddingBase64 { get; set; }
}
Product has a ReadOnlyMemory
public class Product
{
...
[NotMapped, JsonConverter(typeof(EmbeddingJsonConverter))]
public required ReadOnlyMemory<float> NameEmbedding { get; set; }
}
ManualChunk has a byte[] Embedding property:
public class ManualChunk
{
...
public required byte[] Embedding { get; set; }
}
Serialization of embeddings
Another interesting point about the embeddings is the three different ways the get serialized:
ProductCategoryIngestor uses a utility method ToBase64():
private static string ToBase64(ReadOnlyMemory<float> embedding)
=> Convert.ToBase64String(MemoryMarshal.AsBytes(embedding.Span));
ProductInjestor uses the custom JsonConverter attribute for the EmbeddingJsonConverter shown earlier
ManualIngestor uses the JsonSerializer that converts a byte array to a base 64 string
PdfPig usage
I’ve see PdfPig used in other projects before, however I have not seen the techniques used to get the words and text blocks used in this project:
private static string GetPageText(Page pdfPage)
{
var letters = pdfPage.Letters;
var words = NearestNeighbourWordExtractor.Instance.GetWords(letters);
var textBlocks = DocstrumBoundingBoxes.Instance.GetBlocks(words);
return string.Join(Environment.NewLine + Environment.NewLine,
textBlocks.Select(t => t.Text.ReplaceLineEndings(" ")));
}
IEnumerable.Zip usage
One of the great things about reading through open source projects is seeing the way others write code. In the DataIngestor project, the usage of the Enumerable.Zip Method is not something I see very often and seems like an efficient way to write that code:
ManualIngestor.cs
var paragraphsWithEmbeddings = paragraphs.Zip(await embeddingGenerator.GenerateEmbeddingsAsync(paragraphs));
Thoughts on Improvements
This is a pretty straightforward project and there are not too many things I see that need changed, however I did come up with a couple of items that would be nice to have.
Ability to Save to Databases
Due to the name of the project being DataIngestor, I would really like to have at least an option to configure the final steps to do the actual saving to the databases.
Reformat the Project in Visual Studio
I would move the Ingestors to an Ingestors folder (like the Generators being in a Generators folder in the DataGenerator project).
Things I still need to learn
- Is there a reason for the three different property types for embeddings?
- Does
IsAspireHostin the csproj file, need to be true? If so, why?
Other Resources
- eShopSupport Github
- How to add genuinely useful AI to your webapp (not just chatbots) - Steve Sanderson
- smartcomponents Github
- Semantic Kernel Github
- Onnx Runtime
If you have a comment, please message me @haleyjason on twitter/X.