This is the third part of the eShopSupport Series which covers the details of the eShopSupport GitHub repository.
Evaluator Project
The Evaluator project is a console application used to evaluate the chat portion of the application provided by the AssistantApi in the Backend project. The Evaluator application uses the questions in the evalquestions.json file to test the assistant API and scores the results it returns against the answers in that JSON file. This gives you the ability to measure the quality of the chat functionality - which is an important thing to do when you are building application functionality that depends on an LLM.
The Evaluator project is located in in the src folder:
In this entry I’ll cover the details of how the Evaluator application works, a few things I found interesting and some thoughts on improvements.
NOTE: If you have already gotten the eShopSupport application up and running on your system, chances are your vector db docker image has already cached the manual chunks. This means if you change the generated files (like mentioned in the last two entries), you are most likely going to be getting really low scores when evaluating - this is due to the newly generated manual chunks not replacing the original manual chunks in the vector database. So if your evaluator results are really low, try deleting your docker volume eshopsupport-vector-db-storage and rerunning eShopSupport to load in the new manual chunks.
What does it do?
Steve Sanderson mentions this project around 46 minutes into his NDC talk “How to add genuinely useful AI to your webapp (not just chatbots)”, with the subheading of “Evaluation / test”:
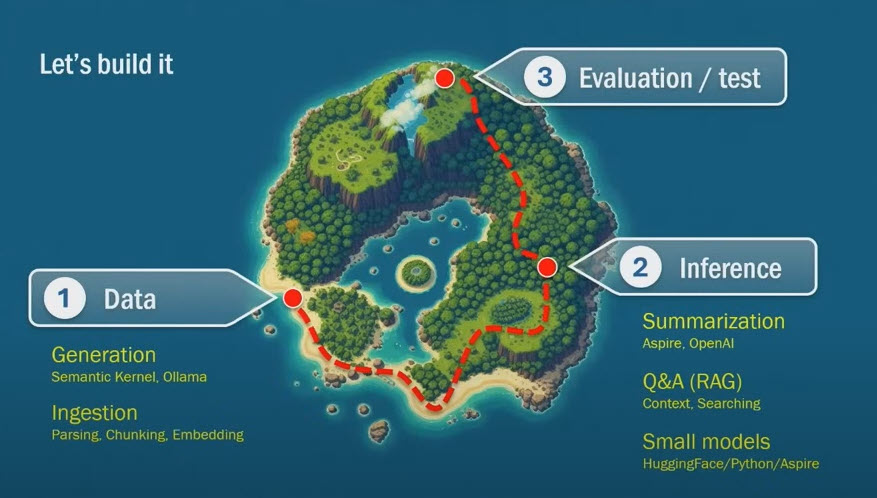
He then gives a good overview of what it is and how it works. I would suggest watching that portion of the video before reading this entry.
The evalquestions.json file
The starting point really is the evalquestions.json file. In an earlier post I covered how the evaluation question/answer pairs were generated and also combined into a single file. These question/answer pairs look like this:
{
"QuestionId": 1,
"ProductId": 44,
"Question": "can I use underwater?",
"Answer": "Not waterproof."
},
The questions in the JSON file have a reasonable question generated from the manual text with a ground truth answer that was generated from the manual itself. If you ran the DataGenerator project, you will have all the intermediate JSON files. However if you didn’t do this, let me briefly look at those files.
For the above question/answer pair, it started in the file evalquestion/44.json with this JSON:
{
"questionId": 1,
"productId": 44,
"question": "can I use underwater?",
"answer": "Not waterproof.",
"verbatimQuoteFromManual": "not waterproof"
}
In this case the answer and the verbatimQuoteFromManual are the same, but that isn’t always the case. Which means, the first step in quality control is to verify these files and make sure the answer and verbatimQuoteFromManual are reasonably the same for your system.
The markdown for the manual to trace the source of the answer is in the file manuals/full/44.md. When I search that markdown file for the verbatimQuoteFromManual, it is found on line 202:

When you read the text in the markdown above, you need to remember these are generated from a prompt we sent to the LLM so the quality is only as good as we asked for.
Now that we’ve looked at the source of the data we are using to test the system, let’s look at how that works.
Configure the system under test
Like with integration tests, the first thing the Evaluation application does is setup the system under test - which is the AssistantApi in the Backend project.
var assistantAnsweringSemaphore = new SemaphoreSlim(/* parallelism */ 3);
var backend = await DevToolBackendClient.GetDevToolStaffBackendClientAsync(
identityServerHttpClient: new HttpClient { BaseAddress = new Uri("https://localhost:7275/") },
backendHttpClient: new HttpClient { BaseAddress = new Uri("https://localhost:7223/") });
Since the AssistantApi is an endpoint that requires authentication, the code does a pretty neat thing and uses a special DevToolBackendClient class to provide a pre-authenticated test client.
The system uses Duende’s Identity Server for authentication. If you aren’t familiar with it, it is an OpenID Connect and OAuth 2 framework written in C#.
With eShopSupport, they have not connected Identity Server to a database and are only using the in memory stores (this configuration is in the IdentityServer/HostingExtensions.cs:
internal static class HostingExtensions
{
public static WebApplication ConfigureServices(this WebApplicationBuilder builder)
{
builder.Services.AddRazorPages();
builder.Services.AddIdentityServer(options =>
{
// https://docs.duendesoftware.com/identityserver/v6/fundamentals/resources/api_scopes#authorization-based-on-scopes
options.EmitStaticAudienceClaim = true;
})
.AddInMemoryIdentityResources(Config.IdentityResources)
.AddInMemoryApiScopes(Config.ApiScopes)
.AddInMemoryClients(Config.GetClients(builder.Configuration))
#if DEBUG
.AddTestUsers(TestUsers.Users)
#endif
;
return builder.Build();
}
In the line above with .AddInMemoryClients(Config.GetClients(builder.Configuration)) is where the client used by the DevToolBackendClient is configured:
public static IEnumerable<Client> GetClients(IConfiguration configuration) =>
[
new Client
{
// This is used by E2E test and evaluation
ClientId = "dev-and-test-tools",
ClientSecrets = { new Secret("dev-and-test-tools-secret".Sha256()) },
AllowedGrantTypes = GrantTypes.ClientCredentials,
AllowedScopes = { "staff-api" },
ClientClaimsPrefix = null,
Claims = { new("role", "staff") }
},
The DevToolBackendClient.GetDevToolStaffBackendClientAsync() uses some extension methods to get a client credential added to the backend httpClient for running the evaluations:
public static async Task<StaffBackendClient> GetDevToolStaffBackendClientAsync(HttpClient identityServerHttpClient, HttpClient backendHttpClient)
{
var identityServerDisco = await identityServerHttpClient.GetDiscoveryDocumentAsync();
if (identityServerDisco.IsError)
{
throw new InvalidOperationException(identityServerDisco.Error);
}
var tokenResponse = await identityServerHttpClient.RequestClientCredentialsTokenAsync(new ClientCredentialsTokenRequest
{
Address = identityServerDisco.TokenEndpoint,
ClientId = "dev-and-test-tools",
ClientSecret = "dev-and-test-tools-secret",
Scope = "staff-api"
});
backendHttpClient.SetBearerToken(tokenResponse.AccessToken!);
return new StaffBackendClient(backendHttpClient);
}
The next few lines in the Evaluator’s Program.cs file, provides more setup:
- configure the LLM to be used from the
appsettings.jsonandappsettings.Local.jsonfiles - load the evalquestions.json file
- create a log file for writing the results to
var chatCompletion = GetChatCompletionService("chatcompletion");
var questions = LoadEvaluationQuestions().OrderBy(q => q.QuestionId);
using var logFile = File.Open("log.txt", FileMode.Create, FileAccess.Write, FileShare.Read);
using var log = new StreamWriter(logFile);
The remaining setup is for the Parallel.ForEachAsync that is the center piece of evaluating the question/answer pairs.
The loop is configured to loop in chunks of 5 using the Enumerable.Chunk method - something I don’t see used a lot.
var questionBatches = questions.Chunk(5);
var scoringParallelism = 4;
var allScores = new List<double>();
var allDurations = new List<TimeSpan>();
await Parallel.ForEachAsync(questionBatches, new ParallelOptions { MaxDegreeOfParallelism = scoringParallelism }, async (batch, cancellationToken) =>
{
...
}
Evaluations and scoring
The actual evaluations and scoring are done inside the loop. It starts with a call to the GetAssistantAnswerAsync
var assistantAnswers = await Task.WhenAll(batch.Select(GetAssistantAnswerAsync));
This is where the information from the JSON file is used to call the AssistantApi with the ProductId and Question:
Console.WriteLine($"Asking question {question.QuestionId}...");
var responseItems = backend.AssistantChatAsync(new AssistantChatRequest(
question.ProductId,
null,
null,
null,
[new() { IsAssistant = true, Text = question.Question }]),
CancellationToken.None);
var answerBuilder = new StringBuilder();
await foreach (var item in responseItems)
{
if (item.Type == AssistantChatReplyItemType.AnswerChunk)
{
answerBuilder.Append(item.Text);
}
}
var duration = DateTime.Now - startTime;
var finalAnswer = answerBuilder.ToString();
Console.WriteLine($"Received answer to question {question.QuestionId}");
return (string.IsNullOrWhiteSpace(finalAnswer) ? "No answer provided" : finalAnswer, duration);
NOTE: the response is a streaming response and has to collect all the tokens being returned into a
StringBuilderin order to get the final answer. This may be useful in your own projects.
I will go into more detail on what the AssistantChatAsync call does in a future post, for this post it is good to say it is the functionality that runs the RAG (retrieval augmented generation) functionality and calls the vector db lookup and LLM to answer the question.
Once all the 5 questions in the batch have been answered, the code goes on to score those 5 questions:
var scores = await ScoreAnswersAsync(batch.Zip(assistantAnswers.Select(a => a.Answer)).ToList());
The ScoreAnswersAsync method takes in the 5 questions, the answer that was in the original JSON file and the answer the AssistantChatAsync returned from the LLM. A prompt is built asking the LLM to score how the AssistantApi did for all 5. For example:
There is an AI assistant that answers questions about products sold by an online retailer. The questions
may be asked by customers or by customer support agents.
You are evaluating the quality of an AI assistant's response to several questions. Here are the
questions, the desired true answers, and the answers given by the AI system:
<questions>
<question index="0">
<text>How to access essentials?</text>
<truth>Unzip the main compartment</truth>
<assistantAnswer>To access your essentials in the HydraHike Hydration Pack, start by unzipping the main compartment. Inside, you'll find multiple pockets and compartments, including special ones for your phone, snacks, and keys. Additionally, the pack has a bungee cord on the exterior for securing extra clothing or a light jacket <cite searchResultId=1802>unzip the main compartment</cite>.</assistantAnswer>
</question>
<question index="1">
<text>What are the overheating precautions?</text>
<truth>Do not leave in direct sunlight for extended periods.</truth>
<assistantAnswer>If the SunShift 100W Solar Charger is overheating, take the following steps:
1. Disconnect the charging cable and allow the solar charger to cool down.
2. Move the solar charger to a shaded area to prevent further overheating.
3. Do not attempt to use the solar charger until it has cooled down to a safe temperature.
If the overheating issue continues, discontinue use of the solar charger and contact Ecovolt Customer Service immediately <cite searchResultId=3139>disconnect the charging cable and allow the solar charger to cool down</cite>.</assistantAnswer>
</question>
<question index="2">
<text>Hi there, I recently purchased the Summit 3000 Trekking Backpack and I'm having issues with the strap adjustment. Can you provide me with the specified torque value for the strap adjustment bolts?</text>
<truth>15-20 Nm</truth>
<assistantAnswer>The specified torque value for the strap adjustment bolts on the Summit 3000 Trekking Backpack is 15-20 Nm <cite searchResultId=5745>"15-20 Nm"</cite>.</assistantAnswer>
</question>
<question index="3">
<text>What is included in the set?</text>
<truth>2-quart pot, 1-quart pot, 7.5-inch frying pan, 2 lids, Mesh carry bag</truth>
<assistantAnswer>The Alpine Camp Cookware Set includes the following items:
1. 2-quart pot
2. 1-quart pot
3. 7.5-inch frying pan
4. 2 lids
5. Mesh carry bag
<cite searchResultId=3654>2-quart pot, 1-quart pot, 7.5-inch frying pan, 2 lids, Mesh carry bag</cite></assistantAnswer>
</question>
<question index="4">
<text>How to turn on the purifier?</text>
<truth>Press and hold power button for 3 seconds.</truth>
<assistantAnswer>To turn on the PureStream Water Purifier, locate the power button on the side of the device. Press and hold the power button for 3 seconds to activate the purifier. The LED indicator light will illuminate to indicate that the device is on <cite searchResultId=3483>"press and hold it for 3 seconds"</cite>.</assistantAnswer>
</question>
</questions>
Evaluate each of the assistant's answers separately by replying in this JSON format:
{
"scores": [
{ "index": 0, "descriptionOfQuality": string, "scoreLabel": string },
{ "index": 1, "descriptionOfQuality": string, "scoreLabel": string },
... etc ...
]
]
Score only based on whether the assistant's answer is true and answers the question. As long as the
answer covers the question and is consistent with the truth, it should score as perfect. There is
no penalty for giving extra on-topic information or advice. Only penalize for missing necessary facts
or being misleading.
The descriptionOfQuality should be up to 5 words summarizing to what extent the assistant answer
is correct and sufficient.
Based on descriptionOfQuality, the scoreLabel must be one of the following labels, from worst to best: Awful, Poor, Good, Perfect
Do not use any other words for scoreLabel. You may only pick one of those labels.
The LLM responds with a JSON structure of the 5 scores:
{
"scores": [
{ "index": 0, "descriptionOfQuality": "Correct and sufficient", "scoreLabel": "Perfect" },
{ "index": 1, "descriptionOfQuality": "Correct but incomplete", "scoreLabel": "Good" },
{ "index": 2, "descriptionOfQuality": "Correct and sufficient", "scoreLabel": "Perfect" },
{ "index": 3, "descriptionOfQuality": "Correct and sufficient", "scoreLabel": "Perfect" },
{ "index": 4, "descriptionOfQuality": "Correct and sufficient", "scoreLabel": "Perfect" }
]
}
A little math is done for creating a numeric score:
var labelIndex = scoreWords.FindIndex(w => w.Equals(s.ScoreLabel, StringComparison.OrdinalIgnoreCase));
return (labelIndex < 0 ? (double?)null : ((double)labelIndex) / (scoreWords.Count - 1), s.DescriptionOfQuality);
There are 4 items in the scoreWords list: List<string> scoreWords = ["Awful", "Poor", "Good", "Perfect"];:
- Awful = 0
- Poor = .33
- Good = .66
- Perfect = 1
Once completely through the list of questions the average score and durations are written out:
var message = $"After {allScores.Count} questions: average score = {allScores.Average():F3}, average duration = {allDurations.Select(d => d.TotalMilliseconds).Average():F3}ms";
I didn’t point it out earlier, but the duration is calculated in the GetAssistantAnswerAsync method for each call to the AssistantApi and returned with the final answer.
Logging
Once you have run the Evaluator, a log.txt file will be created in your bin directory. This file has all the details from the session:
Question ID: 16
Question: check battery level
True answer: Press the Battery Indicator button.
Assistant answer: To check the battery level of the Predictive WeatherShell, gently press the Battery Indicator button located on the inner seam of the jacket <cite searchResultId=18442>press the Battery Indicator button</cite>.
Assistant duration: 00:00:01.9900173
Score: 1
Justification: Correct and sufficient
Question ID: 17
Question: warranty contact phone
True answer: +1-800-123-4567
Assistant answer: For warranty claims or support inquiries regarding the HydratePro Electrolyte Bottle 32oz, you can contact Electro Flow customer support at:
**Phone:** +1-800-123-4567 (Mon-Fri 9 AM to 5 PM ET) <cite searchResultId=3252>Phone: +1-800-123-4567</cite>.
Assistant duration: 00:00:03.0917910
Score: 1
Justification: Correct and sufficient
Question ID: 18
Question: main shaft parts?
True answer: Upper Shaft, Middle Shaft
Assistant answer: The main shaft of the UltraLight Poles 250 is composed of three segments: the Upper Shaft, the Middle Shaft, and the Lower Shaft. The Upper Shaft is the topmost part, followed by the Middle Shaft, and finally the Lower Shaft, which supports the terminal elements of the pole <cite searchResultId=12698>Upper Shaft</cite>.
Assistant duration: 00:00:02.2033012
Score: 1
Justification: Correct but extra
...
NOTE: due to the parallel running of questions, they don’t get logged in numeric order.
Dependencies
The Evaluator project uses the Identity Server endpoint and references the Backend and ServiceDefaults projects. It is best if you are going to be running the Evaluator to verify you can login to the StaffWebUI - if that works then the Evaluator should work.
How to set it up
By default the Evaluator looks for the evalquestions.json file at the location set in the Evaluator.csproj files:
<AssemblyAttribute Include="System.Reflection.AssemblyMetadataAttribute">
<_Parameter1>EvalQuestionsJsonPath</_Parameter1>
<_Parameter2>$(SolutionDir)seeddata\dev\evalquestions.json</_Parameter2>
</AssemblyAttribute>
On my machine, the above creates an AssemblyMetadata attribute on the Evaluator.exe like this:
[assembly: AssemblyMetadata("EvalQuestionsJsonPath", "D:\\eShopSupport\\seeddata\\dev\\evalquestions.json")]
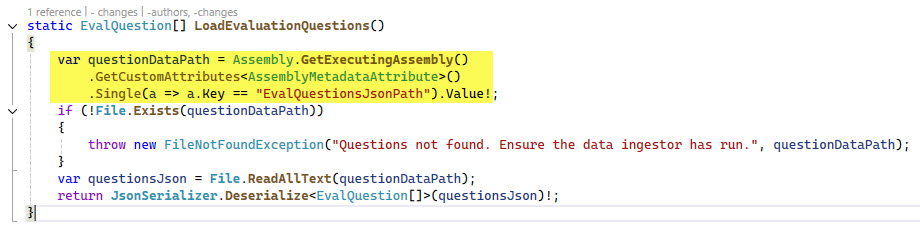
Which is loaded in the LoadEvaluationQuestions method:
Unless you have changed something, you will be able to run the Evaluator once you have successfully started up the AppHost and gotten the eShopSupport working.
Points of Interest
These are some points in the code base that I found interesting and will be revisiting when writing my own code.
Usage of a pre-authenticated backend client
I have used Identity Server (and other OpenID Connect) systems in the past and always run into problems with integration tests - so I like the approach taken in the DevToolBackendClient.
The scoring logic
The non-numerical approach of scoring in the prompt is nice and seems like it would me more effective than asking the LLM to rate with a number. I also like the batching of sending 5 questions in one prompt call in order to cut down on calls to the LLM.
IEnumerable.Chunk, IEnumerable.Average, IEnumerable.Zip usage
I have to admit, it has been a long time since I’ve used some of these extensions on IEnumerable. The usage of Chunk seems like the perfect use case for that method. The same with Average and Zip.
Thoughts on Improvements
My following thoughts on improvements are really due to me wanting more of a reusable evaluation framework written in C# - not really trying to say anything negative here.
Change the way the JSON file is located
I’d like a flexible, config file driven way to get the JSON file to the console application. A hard-coded attribute isn’t too flexible.
Restructure code
I have in mind a utility that has parameters/arguments to enable/disable evaluation features, so I would refactor the code to move the evaluation and scoring into other classes.
Factor prompts into files
This is another move for flexibility. I like having the prompts extracted and in their own text files so it is easier to version and track changes on just the prompts.
More features like ai-rag-chat-evaluator
Currently I don’t think the azure-ai-generative SDK has a C# equivalent so I can’t port Pamela Fox’s evaluator framework over to C# - however I do think Steven Sanderson has provided the foundation code in this eShopSupport code base that could resolve that.
Other Resources
- eShopSupport Github
- How to add genuinely useful AI to your webapp (not just chatbots) - Steve Sanderson
If you have a comment, please message me @haleyjason on twitter/X.