Custom Azure AI Search Skill to Convert Markdown Tables to JSON
I was recently asked what options there are for handling large tables in PDFs, when ingesting files for a RAG application. The question was concerning a retrieval system that was having a problem identifying relevant data in some tables. The problem seemed to be due to the headings not being in the same chunk as the data - so the data doesn’t have any context to indicate its meaning.
This blog by Lu Zhang (Microsoft) - A Heuristic Method of Merging Cross-Page Tables based on Document Intelligence Layout Model describes how to identify and merge tables using the Azure AI Document Intelligence Layout Model, she also provides working code to do it on GitHub. She goes over how to get the tables, locate them and figure out how to stitch them together. After looking over her code, I decided to try a simpler approach first to see if it would solve the problem: convert the table data as JSON.
NOTE: Lu Zhang’s approach deals with tables that span pages or don’t have headers on each page. My solution only works for long tables on a single page or multi-page tables when the headers are on each page.
Technologies involved
- Azure AI Search indexer to ingest PDF files
- An existing skillset (pipeline) configured for the processing steps
- Using the Document Layout skill for ingesting PDFs
The original skillset performs these steps:
- Use the DocumentIntelligenceLayoutSkill to parse the PDF and provide markdown
- Use the SplitSkill to “chunk” the data into pages before getting the embeddings
- Use the AzureOpenAIEmbeddingSkill to get the embeddings for the chunks/pages
Example
I had Copilot in Word generate a sample document for me with a large table of text on it:
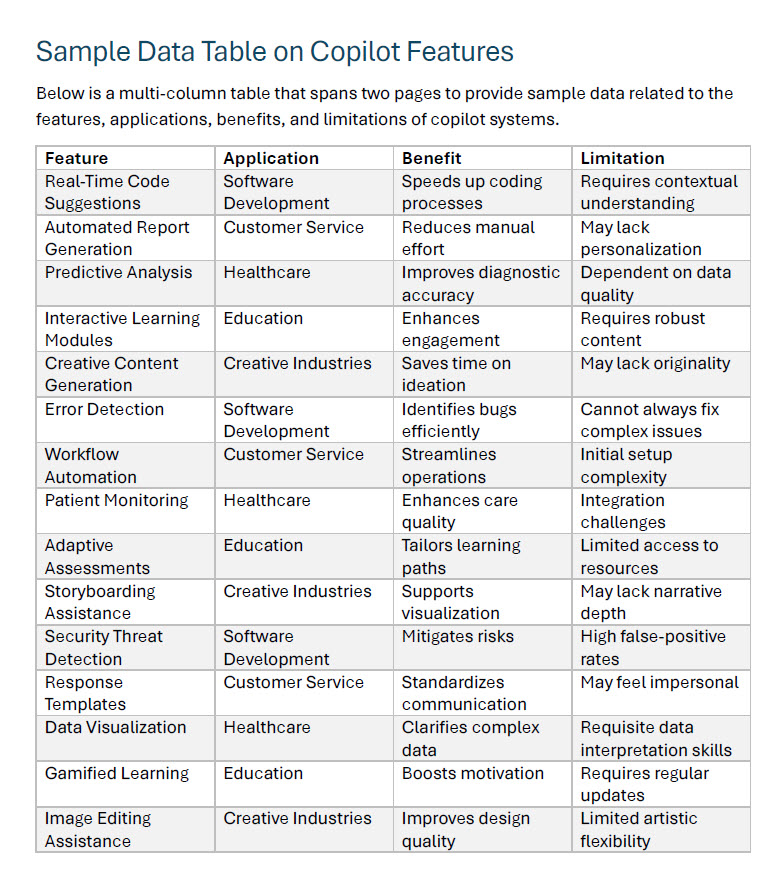
Before using the custom skill
The DocumentLayoutSkill will create valid HTML tables (not the usual pipe markdown tables), so the original chunks created from the skillset look like this:
Chunk 1:
Below is a multi-column table that spans two pages to provide sample data related to the\r\nfeatures, applications, benefits, and limitations of copilot systems.\r\n\r\n\r\n<table>\r\n<tr>\r\n<th>Feature</th>\r\n<th>Application</th>\r\n<th>Benefit</th>\r\n<th>Limitation</th>\r\n</tr>\r\n<tr>\r\n<td>Real-Time Code Suggestions</td>\r\n<td>Software Development</td>\r\n<td>Speeds up coding processes</td>\r\n<td>Requires contextual understanding</td>\r\n</tr>\r\n<tr>\r\n<td>Automated Report Generation</td>\r\n<td>Customer Service</td>\r\n<td>Reduces manual effort</td>\r\n<td>May lack personalization</td>\r\n</tr>\r\n<tr>\r\n<td>Predictive Analysis</td>\r\n<td>Healthcare</td>\r\n<td>Improves diagnostic accuracy</td>\r\n<td>Dependent on data quality</td>\r\n</tr>\r\n<tr>\r\n<td>Interactive Learning Modules</td>\r\n<td>Education</td>\r\n<td>Enhances engagement</td>\r\n<td>Requires robust content</td>\r\n</tr>\r\n<tr>\r\n<td>Creative Content Generation</td>\r\n<td>Creative Industries</td>\r\n<td>Saves time on ideation</td>\r\n<td>May lack originality</td>\r\n</tr>\r\n<tr>\r\n<td>Error Detection</td>\r\n<td>Software Development</td>\r\n<td>Identifies bugs efficiently</td>\r\n<td>Cannot always fix complex issues</td>\r\n</tr>\r\n<tr>\r\n<td>Workflow Automation</td>\r\n<td>Customer Service</td>\r\n<td>Streamlines operations</td>\r\n<td>Initial setup complexity</td>\r\n</tr>\r\n<tr>\r\n<td>Patient Monitoring</td>\r\n<td>Healthcare</td>\r\n<td>Enhances care quality</td>\r\n<td>Integration challenges</td>\r\n</tr>\r\n<tr>\r\n<td>Adaptive Assessments</td>\r\n<td>Education</td>\r\n<td>Tailors learning paths</td>\r\n<td>Limited access to resources</td>\r\n</tr>\r\n<tr>\r\n<td>Storyboarding Assistance</td>\r\n<td>Creative Industries</td>\r\n<td>Supports visualization</td>\r\n<td>May lack narrative depth</td>\r\n</tr>\r\n<tr>\r\n<td>Security Threat Detection</td>\r\n<td>Software Development</td>\r\n<td>Mitigates risks</td>\r\n<td>High false-positive rates</td>\r\n</tr>\r\n<tr>\r\n<td>Response Templates</td>\r\n<td>Customer Service</td>\r\n<td>Standardizes communication</td>\r\n<td>May feel impersonal</td>\r\n</tr>\r\n<tr>
Chunk 2:
learning paths</td>\r\n<td>Limited access to resources</td>\r\n</tr>\r\n<tr>\r\n<td>Storyboarding Assistance</td>\r\n<td>Creative Industries</td>\r\n<td>Supports visualization</td>\r\n<td>May lack narrative depth</td>\r\n</tr>\r\n<tr>\r\n<td>Security Threat Detection</td>\r\n<td>Software Development</td>\r\n<td>Mitigates risks</td>\r\n<td>High false-positive rates</td>\r\n</tr>\r\n<tr>\r\n<td>Response Templates</td>\r\n<td>Customer Service</td>\r\n<td>Standardizes communication</td>\r\n<td>May feel impersonal</td>\r\n</tr>\r\n<tr>\r\n<td>Data Visualization</td>\r\n<td>Healthcare</td>\r\n<td>Clarifies complex data</td>\r\n<td>Requisite data interpretation skills</td>\r\n</tr>\r\n<tr>\r\n<td>Gamified Learning</td>\r\n<td>Education</td>\r\n<td>Boosts motivation</td>\r\n<td>Requires regular updates</td>\r\n</tr>\r\n<tr>\r\n<td>Image Editing Assistance</td>\r\n<td>Creative Industries</td>\r\n<td>Improves design quality</td>\r\n<td>Limited artistic flexibility</td>\r\n</tr>\r\n</table>
If you look at the second chunk, you’ll notice there is an overlap on the chunking and there are no headers. So all the data in that chunk isn’t able to be identified as Feature, Application, Benefit or Limitation - like the first chunk will.
After using the custom skill
The custom skill is inserted in the skillset after the DocumentIntelligenceLayoutSkill step, so the tables can be modified and used in the chunking step afterward.
The chunks created with the JSON version of the tables look like this:
Chunk 1:
Below is a multi-column table that spans two pages to provide sample data related to the features, applications, benefits, and limitations of copilot systems.\n```json\n[ { \"Feature\": \"Real-Time Code Suggestions\", \"Application\": \"Software Development\", \"Benefit\": \"Speeds up coding processes\", \"Limitation\": \"Requires contextual understanding\" }, { \"Feature\": \"Automated Report Generation\", \"Application\": \"Customer Service\", \"Benefit\": \"Reduces manual effort\", \"Limitation\": \"May lack personalization\" }, { \"Feature\": \"Predictive Analysis\", \"Application\": \"Healthcare\", \"Benefit\": \"Improves diagnostic accuracy\", \"Limitation\": \"Dependent on data quality\" }, { \"Feature\": \"Interactive Learning Modules\", \"Application\": \"Education\", \"Benefit\": \"Enhances engagement\", \"Limitation\": \"Requires robust content\" }, { \"Feature\": \"Creative Content Generation\", \"Application\": \"Creative Industries\", \"Benefit\": \"Saves time on ideation\", \"Limitation\": \"May lack originality\" }, { \"Feature\": \"Error Detection\", \"Application\": \"Software Development\", \"Benefit\": \"Identifies bugs efficiently\", \"Limitation\": \"Cannot always fix complex issues\" }, { \"Feature\": \"Workflow Automation\", \"Application\": \"Customer Service\", \"Benefit\": \"Streamlines operations\", \"Limitation\": \"Initial setup complexity\" }, { \"Feature\": \"Patient Monitoring\", \"Application\": \"Healthcare\", \"Benefit\": \"Enhances care quality\", \"Limitation\": \"Integration challenges\" }, { \"Feature\": \"Adaptive Assessments\", \"Application\": \"Education\", \"Benefit\": \"Tailors learning paths\", \"Limitation\":
Chunk 2:
Cannot always fix complex issues\" }, { \"Feature\": \"Workflow Automation\", \"Application\": \"Customer Service\", \"Benefit\": \"Streamlines operations\", \"Limitation\": \"Initial setup complexity\" }, { \"Feature\": \"Patient Monitoring\", \"Application\": \"Healthcare\", \"Benefit\": \"Enhances care quality\", \"Limitation\": \"Integration challenges\" }, { \"Feature\": \"Adaptive Assessments\", \"Application\": \"Education\", \"Benefit\": \"Tailors learning paths\", \"Limitation\": \"Limited access to resources\" }, { \"Feature\": \"Storyboarding Assistance\", \"Application\": \"Creative Industries\", \"Benefit\": \"Supports visualization\", \"Limitation\": \"May lack narrative depth\" }, { \"Feature\": \"Security Threat Detection\", \"Application\": \"Software Development\", \"Benefit\": \"Mitigates risks\", \"Limitation\": \"High false-positive rates\" }, { \"Feature\": \"Response Templates\", \"Application\": \"Customer Service\", \"Benefit\": \"Standardizes communication\", \"Limitation\": \"May feel impersonal\" }, { \"Feature\": \"Data Visualization\", \"Application\": \"Healthcare\", \"Benefit\": \"Clarifies complex data\", \"Limitation\": \"Requisite data interpretation skills\" }, { \"Feature\": \"Gamified Learning\", \"Application\": \"Education\", \"Benefit\": \"Boosts motivation\", \"Limitation\": \"Requires regular updates\" }, { \"Feature\": \"Image Editing Assistance\", \"Application\": \"Creative Industries\", \"Benefit\": \"Improves design quality\", \"Limitation\": \"Limited artistic flexibility\" }]\n```
Now if you look at either chunk, you’ll see they look like normal JSON, with a property and value. This allows the data to be identified with its corresponding header, giving it more context for a retrieval system.
The Code
The code is in GitHub: table-converter and is a python API app designed to be run as an Azure Function.
The bulk of the logic is in table_converter.py parse_html_table() method:
def parse_html_table(table):
header_rows = []
# Try to collect rows with <th> as headers
for tr in table.find_all("tr"):
if tr.find("th"):
expanded = expand_row(tr.find_all(["th", "td"]))
header_rows.append(expanded)
else:
break
if header_rows:
flat_headers = flatten_headers(header_rows)
data_start_index = len(header_rows)
else:
flat_headers = []
data_start_index = 0
# Parse body rows
body_rows = []
trs = table.find_all("tr")[data_start_index:]
for tr in trs:
cells = expand_row(tr.find_all(["td", "th"]))
if not cells:
continue
if not flat_headers:
flat_headers = [f"Column {i+1}" for i in range(len(cells))]
row = {}
header_counts = {}
for header, cell in zip(flat_headers, cells):
if header in header_counts:
header_counts[header] += 1
row[f"{header} {header_counts[header]}"] = cell
else:
header_counts[header] = 0
row[header] = cell
body_rows.append(row)
return body_rows
To use it, you’ll need to deploy it to Azure and insert it into your skillset like this:
//... Doc intelligence Skill above it ...
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "JSON table converter",
"description": "Converts tables in markdown to JSON.",
"context": "/document/markdownDocument/*",
"uri": "https://<func site>.azurewebsites.net/convert",
"httpMethod": "POST",
"timeout": "PT3M50S",
"batchSize": 10,
"inputs": [
{
"name": "text",
"source": "/document/markdownDocument/*/content",
"inputs": []
}
],
"outputs": [
{
"name": "text",
"targetName": "markdown_content"
}
],
"httpHeaders": {
"x-functions-key": "<func key>"
}
},
//... Splitskill below it ...
NOTE: You’ll need to replace
<func site>with the subdomain of your function and get the master key to replace the<func key>
You will also need to change the inputs on the SplitSkill to use the output markdown_content:
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
// ... other properties are the same
"inputs": [
{
"name": "text",
"source": "/document/markdownDocument/*/markdown_content",
"inputs": []
}
],
// .. output is the same
},
Limitations
As I noted earlier, currently this approach won’t work if Document Intelligence recognizes there are multiple tables and you want the headers from one table carried over to the following table.
Conclusion
This is just a simple example, but I’m sure you can see that Azure AI Search custom skills are very useful and allow you to modify the processing of you data before it gets into the search index.
If you have a comment, please message me @haleyjason on twitter/X.