Last week I wrote about the notebook I created when I was working out the flow of the property graph RAG implementation. In this entry I will go through the two projects I created to provide some reusable code as well as allow for better experimentation:
Related posts:
- Study Notes: Graph RAG - Property Graph RAG
- Study Notes: Graph RAG - Property Graph RAG (The Notebook)
NOTE: In order to get the most out of this blog post, you should first read the related two posts.
Where To Get The Code
The code for this entry is in my Github repo semantic-kernel-getting-started under the samples/demos folder:
PropertyGraphIngestor- is the console application that extracts entities from text documents and populates a Neo4j dbPropertyGraphRAG- is the console application that does property graph RAG using the Neo4j database for both graph information and the vector storage for standard RAG.
A Quick Look at What It Does
Like the notebook, this demo uses a listing of blog post summaries and some metadata about them, here is a small snippet to give you an idea:
...
Title: Study Notes: Text-to-SQL
Author: Jason
Posted On: Friday, July 5, 2024
Topics: AI, Learning, OpenAI, Semantic Kernel, Text-to-SQL, Study Notes Series
Summary: This week I’ve been researching Text-to-SQL (also known as Natural Language to SQL), below are my study notes to compile all the resources I’ve found on the topic to date. There is also a corresponding blog entry that walks through a code example. NOTE: I am approaching this topic specifically looking at how it can be used to extend usage scenarios in a RAG application. Background Text-to-SQL (or Natural Language to SQL) is a pattern where the objective is to have an LLM generate SQL statements for a database using natural language.
...
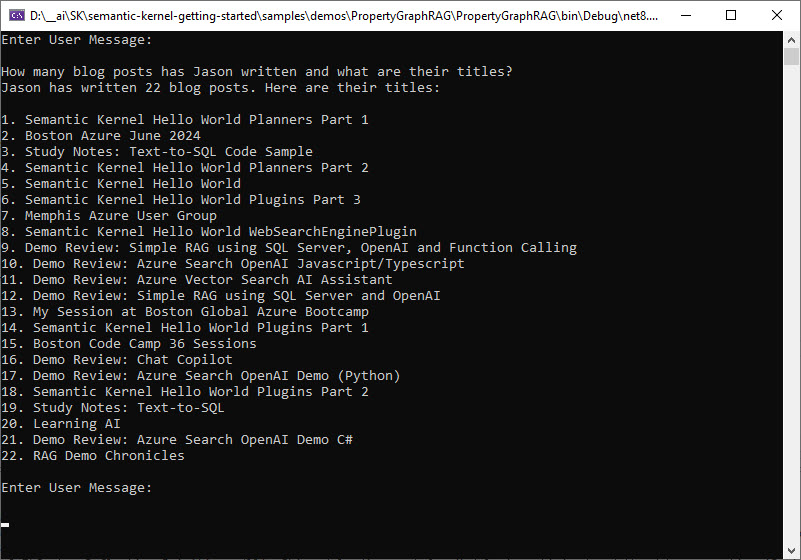
I have the ingestor using individual summary blogs (show above) as a chunk. There are 22 blog summary chunks in that text file, so there are 22 chunks. This makes baseline RAG (using just the most relevant vector search matches) fail at answering global questions like: “How many blogs has Jason written and what are their titles?”
Example using the property graph RAG features:
Example of only using baseline RAG (with a limit of including 5 chunks in the context):
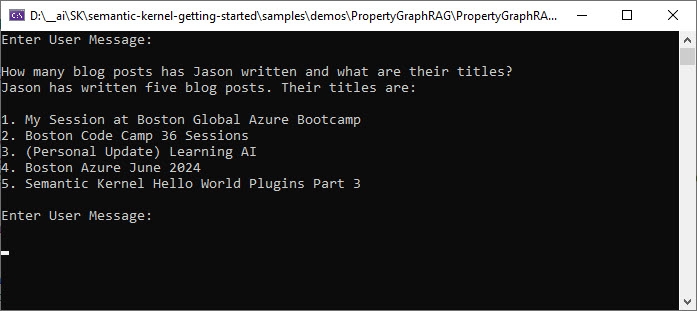
Just as with the notebook, the solution still has its challenges and scenarios where it is not correct.
Once you get the Neo4j db created and the ingestor working with my data file, you can type “run tests” in the console when running the PropertyGraphRAG console to cycle through the following questions:
- What does Jason blog about?
- How many blogs has he written?
- How many blogs has Jason written?
- What blogs has Jason written?
- What has he written about Java?
- How about Python?
- What presentations has he given?
- Are all his blogs about AI in some way?
- What do you know about Code Camp?
- What has Jason mentioned about Boston Azure?
- Which blogs are about Semantic Kernel?
- What blogs are about LangChain?
There are several features to test with the property graph RAG and so far the best I can get is 10 of those questions completely correct (2 and 11 still partially fail). That is better than the 7 correct answers from baseline RAG and I do think I can get those other two items to be 100% correct but just haven’t had the time to get there. If you figure it out before me - please let me know :)

The Code
If you’ve read any of my Hello Semantic Kernel blog posts you’ll notice most of the common code for configuration and Semantic Kernel setup is all the same, but this time I created a common shared project (PropertyGraph.Common) for the common logic so I can use it with both console applications.
Ingestion
If you run the PropertyGraphIngestor.exe on command line, you’ll see the parameters it takes:
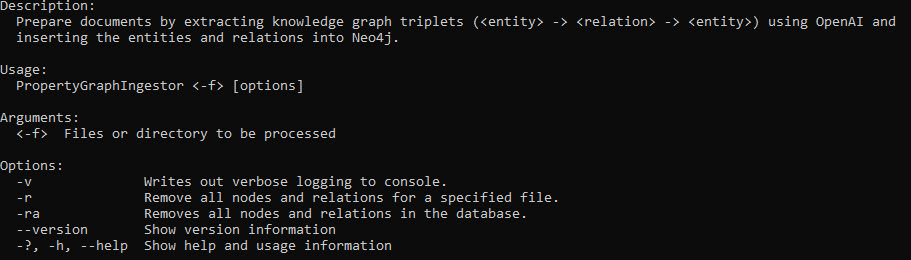
If you run it in Visual Studio, the project should already have these parameters set in the launchSettings.json file:
.\\data\\summaries.txt -v
A file path or directory is required.
I’m not going to get into the detail of the PropertyGraphIngestor console application (since it is only a couple of files that provide interaction with the command line). Instead I’ll cover the logic it uses from the PropertyGraph.Common project to provide its features.
Populate Neo4j Database
This is very similar to the notebook logic, though there are a few differences that I’ll call out.
The Neo4jService.cs class is where the majority of the logic resides. It all starts with the PopulateGraphFromDocumentAsync() method:
public async Task PopulateGraphFromDocumentAsync(string fileName)
{
var cypherText = await GetCypherTextAsync(fileName);
await PopulateGraphAsync(cypherText);
await CreateIndexsIfNeededAsync();
await PopulateEmbeddingsAsync();
}
The GetCypherTextAsync() method is where the first difference between the notebook and project is - a cache file is created after the entity extraction is completed and used on subsequent runs unless you delete that *.cypher file.
NOTE: This cache file helps to not make unnecessary calls to the LLM as well as with understanding the cypher being generated from the extraction process. Plus when working on optimizing the retrieval you may want to modify the cypher to try out scenarios, the modify the prompt later to get the LLM closer to creating the graph you need.
private async Task<string> GetCypherTextAsync(string fileName)
{
string cypherText;
var cacheFile = $"{fileName}.cypher";
if (!File.Exists(cacheFile))
{
_logger.LogInformation("No cached file found.");
var extractor = new TripletsExtractor(_options);
cypherText = await extractor.ExtractAsync(fileName);
File.WriteAllText(cacheFile, cypherText);
}
else
{
_logger.LogInformation("Loading cached file: {cacheFile}.", cacheFile);
cypherText = File.ReadAllText(cacheFile);
}
return cypherText;
}
TripletsExtractor.cs is mostly just a refactoring of the same logic in the notebook - though there a some small differences.
Node Id Creation
The notebook used: Guid.NewGuid().ToString("N") in order to create a unique id for each node.
The TripletExtractor uses a sha1 hash of the text. This is an additional step to help prevent duplicate nodes
public static string CreateId(string text)
{
using (SHA1 sha1 = SHA1.Create())
{
byte[] inputBytes = Encoding.UTF8.GetBytes(text);
byte[] hashBytes = sha1.ComputeHash(inputBytes);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < hashBytes.Length; i++)
{
sb.Append(hashBytes[i].ToString("X2").ToLower());
}
return sb.ToString();
}
}
The data structures used in the entity extraction and cypher creation are all in the DataObjects.cs file - these are the same as the notebook.
The TripletsExtractor.ExtractAsync() method is where the refactoring from the notebook to a proper class shows, it drives the process of the extraction:
public async Task<string> ExtractAsync(string fileName)
{
DocumentMetadata documentMetatdata = new(Utilities.CreateId(fileName), fileName);
var chunks = await ExtractEntitiesFromDocumentChunksAsync(documentMetatdata);
var entities = DeduplicateEntities(chunks);
var cypherText = CreateCypherText(documentMetatdata, chunks, entities);
return cypherText;
}
Before getting into the ExtractEntitiesFromDocumentChunksAsync() method, I should mention the appsettings values that are important for ingestion.
The “PropertyGraph” section in appsettings.json has some settings to help provide options for the entity extraction:
| Setting | Note |
|---|---|
| UseTokenSplitter | true or false to indicate if you want to use a chunk size and overlap or just split on an empty line |
| ChunkSize | token size for the text splitter to use |
| Overlap | token overlap size for the text splitter to use |
| EntityTypes | starter list of entities to include in the prompt. The closer these are to your data file, the better quality graph you end up with |
| RelationTypes | starter list of relation types |
| EntityExtractonTemplatePreamble | text used to provide some specific context in the prompt to help with the entity extraction quality |
| DocumentChunkTypeLabel | this is the value of the label for the document chunks |
| MaxTripletsPerChunk | number of triplets per chunk to ask the LLM to extract |
The ExtractEntitiesFromDocumentChunksAsync() method checks if the source file is available, splits into chunks (using some of the settings above to decide which type of splitting to use), calls the LLM for each chunk and builds a list of the extracted entities.
public async Task<Dictionary<ChunkMetadata, List<TripletRow>>> ExtractEntitiesFromDocumentChunksAsync(DocumentMetadata documentMetatdata)
{
Dictionary<ChunkMetadata, List<TripletRow>> chunks = new Dictionary<ChunkMetadata, List<TripletRow>>();
if (!File.Exists(documentMetatdata.source))
{
_logger.LogInformation($"File '{documentMetatdata.source} not found");
return chunks;
}
List<string> chunkTextList = SplitDocumentIntoChunks(documentMetatdata);
var prompts = _options.Kernel.CreatePluginFromPromptDirectory("Prompts");
for (int i = 0; i < chunkTextList.Count; i++)
{
string text = chunkTextList[i];
string currentDocumentChunk = $"DocumentChunk{i}";
string id = Utilities.CreateId($"{currentDocumentChunk}{documentMetatdata.id}");
ChunkMetadata chunkMetadata = new (id, currentDocumentChunk, i, documentMetatdata.id, text);
var result = await _options.Kernel.InvokePromptAsync<List<TripletRow>>(
prompts["ExtractEntities"],
new() {
{ "maxTripletsPerChunk", _options.PropertyGraph.MaxTripletsPerChunk ?? Defaults.MAX_TRIPLETS_PER_CHUNK },
{ "preamble", _options.PropertyGraph.EntityExtractonTemplatePreamble ?? string.Empty },
{ "entityTypes", _options.PropertyGraph.EntityTypes ?? Defaults.ENTITY_TYPES },
{ "relationTypes", _options.PropertyGraph.RelationshipTypes ?? Defaults.RELATION_TYPES },
{ "text", text },
});
if (result != null)
{
if (result != null && result.Count > 0)
{
chunks.Add(chunkMetadata, result);
}
}
else
{
_logger.LogWarning("ExtractEntities prompt invoke returned null");
}
}
_logger.LogInformation($"Number of chunks: {chunks.Count}");
return chunks;
}
The prompt used is the same as the notebook (currently):
<message role="user">Please extract up to {{$maxTripletsPerChunk}} knowledge triplets from the provied text.
{{$preamble}}
Each triplet should be in the form of (head, relation, tail) with their respective types.
######################
ONTOLOGY:
Entity Types: {{$entityTypes}}
Relation Types: {{$relationTypes}}
Use these entity types and relation types as a starting point, introduce new types if necessary based on the context.
GUIDELINES:
- Output in JSON format: [{""head"": """", ""head_type"": """", ""relation"": """", ""tail"": """", ""tail_type"": """"}]
- Use the full form for entities (ie., 'Artificial Intelligence' instead of 'AI')
- Keep entities and relation names concise (3-5 words max)
- Break down complex phrases into multiple triplets
- Ensure the knowledge graph is coherent and easily understandable
######################
EXAMPLE:
Text: Jason Haley, chief engineer of Jason Haley Consulting, wrote a new blog post titled 'Study Notes: GraphRAG - Property Grids' about creating a property grid RAG system using Semantic Kernel.
Output:
[{""head"": ""Jason Haley"", ""head_type"": ""PERSON"", ""relation"": ""WORKS_FOR"", ""tail"": ""Jason Haley Consulting"", ""tail_type"": ""COMPANY""},
{""head"": ""Study Notes: GraphRAG - Property Grids"", ""head_type"": ""BLOG_POST"", ""relation"": ""WRITTEN_BY"", ""tail"": ""Jason Haley"", ""tail_type"": ""PERSON""},
{""head"": ""Study Notes: GraphRAG - Property Grids"", ""head_type"": ""BLOG_POST"", ""relation"": ""TOPIC"", ""tail"": ""Semantic Kernel"", ""tail_type"": ""TECHNOLOGY""},
{""head"": ""property grid RAG system"", ""head_type"": ""SOFTWARE_SYSTEM"", ""relation"": ""USES"", ""tail"": ""Semantic Kernel"", ""tail_type"": ""TECHNOLOGY""}]
######################
Text: {{$text}}
######################
Output:</message>
The next thing the ExtractAsync() method does is to de-duplicate the extracted entities by calling the DeduplicateEntities() method. This method takes the structure returned from the LLM and creates an entity a dictionary of the entities. It also creates a list of which document chunks mention the entity in order to create a relationship in Neo4j later.
private Dictionary<string, EntityMetadata> DeduplicateEntities(Dictionary<ChunkMetadata, List<TripletRow>> chunks)
{
Dictionary<string, EntityMetadata> entities = new Dictionary<string, EntityMetadata>();
foreach (ChunkMetadata key in chunks.Keys)
{
List<TripletRow> triplets = chunks[key];
foreach (var triplet in triplets)
{
EntityMetadata entity;
string pcHead = Utilities.CreateName(triplet.head);
if (entities.ContainsKey(pcHead))
{
entity = entities[pcHead];
if (!entity.mentionedInChunks.ContainsKey(key.id))
{
entity.mentionedInChunks.Add(key.id, key);
}
}
else
{
entity = new EntityMetadata();
entities.Add(pcHead, Utilities.PopulateEntityMetadata(key, triplet, entity, true));
}
string pcTail = Utilities.CreateName(triplet.tail);
if (entities.ContainsKey(pcTail))
{
entity = entities[pcTail];
if (!entity.mentionedInChunks.ContainsKey(key.id))
{
entity.mentionedInChunks.Add(key.id, key);
}
}
else
{
entity = new EntityMetadata();
entities.Add(pcTail, Utilities.PopulateEntityMetadata(key, triplet, entity, false));
}
}
}
_logger.LogInformation($"Unique entity count: {entities.Count}");
// for logging
foreach (var key in entities.Keys)
{
var e = entities[key];
_logger.LogTrace($"{key} Mentioned In {e.mentionedInChunks.Count} chunks");
}
return entities;
}
The last step in the ExtractAsync() method is the CreateCypherText() method to create the cypher representing all the nodes and relationships we want to create in Neo4j. This method is the same as the notebook logic.
private string CreateCypherText(DocumentMetadata documentMetadata, Dictionary<ChunkMetadata, List<TripletRow>> chunks, Dictionary<string, EntityMetadata> entities)
{
List<string> entityCypherText = new List<string>();
entityCypherText.Add($"MERGE (Document1:DOCUMENT {{ id: '{documentMetadata.id}', name:'Document1', type:'DOCUMENT', source: '{documentMetadata.source}'}})");
string documentChunkType = string.IsNullOrEmpty(_options.PropertyGraph.DocumentChunkTypeLabel) ? Defaults.DOCUMENT_CHUNK_TYPE : _options.PropertyGraph.DocumentChunkTypeLabel;
foreach (var chunk in chunks.Keys)
{
entityCypherText.Add($"MERGE (DocumentChunk{chunk.sequence}:DOCUMENT_CHUNK {{ id: '{chunk.id}', name: '{chunk.name}', type: '{documentChunkType}', documentId: '{chunk.documentId}', source: '{documentMetadata.source}', sequence: '{chunk.sequence}', text: \"{chunk.text.Replace("\"", "'")}\"}})");
entityCypherText.Add($"MERGE (Document1)-[:CONTAINS]->(DocumentChunk{chunk.sequence})");
}
HashSet<string> types = new HashSet<string>();
foreach (var entity in entities.Keys)
{
var labels = entities[entity];
var pcEntity = entity;
// Handle strange issue when type is empty string
if (string.IsNullOrEmpty(labels.type))
{
continue;
}
entityCypherText.Add($"MERGE ({pcEntity}:ENTITY {{ name: '{pcEntity}', type: '{labels.type}', id: '{labels.id}', documentId: '{documentMetadata.id}', source: '{documentMetadata.source}', text: '{labels.text}'}})");
if (!types.Contains(labels.type))
{
types.Add(labels.type);
}
foreach (var key in labels.mentionedInChunks.Keys)
{
var documentChunk = labels.mentionedInChunks[key];
entityCypherText.Add($"MERGE ({pcEntity})-[:MENTIONED_IN]->(DocumentChunk{documentChunk.sequence})");
}
}
HashSet<string> relationships = new HashSet<string>();
foreach (ChunkMetadata key in chunks.Keys)
{
List<TripletRow> triplets = chunks[key];
foreach (var triplet in triplets)
{
var pcHead = Utilities.CreateName(triplet.head);
var pcTail = Utilities.CreateName(triplet.tail);
var relationName = triplet.relation.Replace(" ", "_").Replace("-", "_");
if (string.IsNullOrEmpty(relationName))
{
relationName = "RELATED_TO";
}
entityCypherText.Add($"MERGE ({pcHead})-[:{relationName}]->({pcTail})");
string headRelationship = $"MERGE (DocumentChunk{key.sequence})-[:MENTIONS]->({pcHead})";
if (!relationships.Contains(headRelationship))
{
relationships.Add(headRelationship);
entityCypherText.Add(headRelationship);
}
string tailRelationship = $"MERGE (DocumentChunk{key.sequence})-[:MENTIONS]->({pcTail})";
if (!relationships.Contains(tailRelationship))
{
relationships.Add(tailRelationship);
entityCypherText.Add(tailRelationship);
}
}
}
// For logging
foreach (var t in entityCypherText)
{
_logger.LogTrace(t);
}
StringBuilder all = new StringBuilder();
all.AppendJoin(Environment.NewLine, entityCypherText.ToArray());
return all.ToString();
}
At this point of the process, we now return to the Neo4jService PopulateGraphFromDocumentAsync() method. The cypher text is generated or loaded from the cache file, so no we need to interact with the Neo4j database.
Most of the Neo4j interaction follows these steps:
- Create a session
- Run or execute some cypher text
- If it returns a result use it, otherwise return from the method.
All the cypher text is in the CypherStatements.cs file. Since I’m still new to Neo4j, that is about all I’m going to cover.
If you open the Neo4j explorer, it shows a neat graph of the entities. When you start to change the prompt or generated cypher (or just rerun the LLM calls) you’ll notice differences in the nodes and entities.
MATCH (n) RETURN (n)
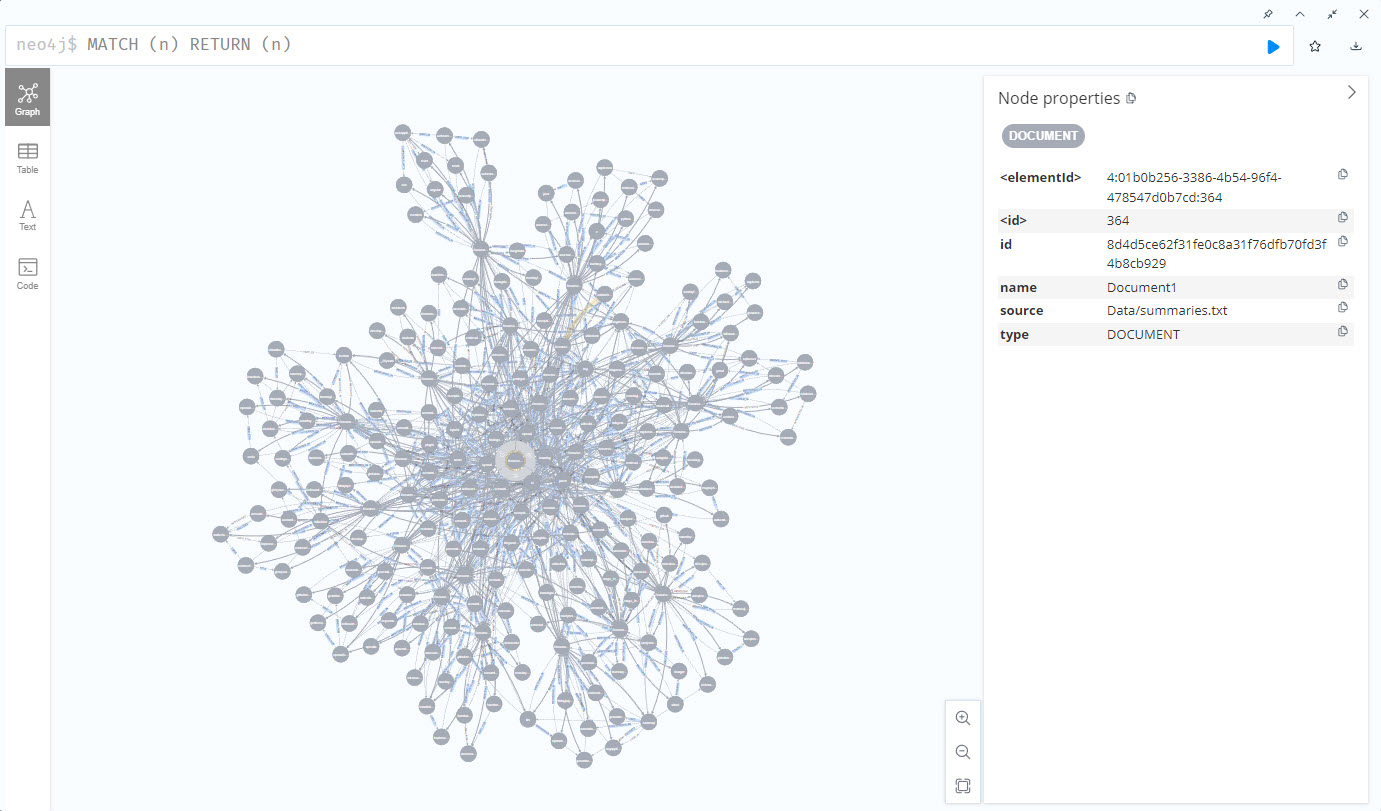
Remove Nodes from a Neo4j Database
There are two levels of removal (deletion) the PropertyGraphIngestor app will do:
-raoption will remove all the nodes and relationships in Neo4j-roption will remove only the nodes and relationships associated with the provided file name
Retrieval
The retrieval section of the Notebook post describes the overall steps a little better than I mention here - so you may want to read it if you haven’t.
Again, if you’ve read any of my Hello Semantic Kernel blog posts the code in the PropertyGraphRAG Program.cs will look familiar.
I added an extension method for ChatHistory which makes it easier to use ChatHistory and stream the result to the console:
ChatHistory chatHistory = new ChatHistory();
PropertyGraphRetriever graphRAGRetriever = new PropertyGraphRetriever(appOptions);
while (true)
{
Console.WriteLine("Enter User Message:");
Console.WriteLine("");
string? userMessage = Console.ReadLine();
...
chatHistory.AddUserMessage(userMessage);
await foreach (StreamingKernelContent update in chatHistory.AddStreamingMessageAsync(await graphRAGRetriever.RetrieveAsync(userMessage)))
{
Console.Write(update);
}
Console.WriteLine("");
Console.WriteLine("");
}
}
Also (as I mentioned earlier) since I am working on improving the overall functionality, I found myself needing to run the same tests over and over - so I added the ability to run through 12 different questions by typing run tests … which both saves me time when tweaking things and makes my tests consistent.
The majority of the logic in this application is in the PropertyGraphRetriever class.
There are nine settings in appsettings.json that effect the retrieval functionality:
| Setting | Note |
|---|---|
| IncludeEntityTextSearch | if true, performs some of the configured steps using the property graph for building a RAG context |
| UseKeywords | if true, will perform a keyword extraction on the user’s request |
| TypeEntityTextOfSearch | if FULL_TEXT, then a full text search is performed on the entity text in Neo4j using the full text index. if VECTOR, then a similarity search is performed on the entity text using a vector index |
| IncludeTriplets | if true, then triplets retrieved from one the entity searches will be included in the RAG context |
| MaxTriplets | the maximum number of triplets to include in the RAG index |
| IncludeRelatedChunks | if true, the the entity search will locate the related document chunks |
| MaxRelatedChunks | the number of related document chunks to include in the RAG context |
| IncludeChunkVectorSearch | if true, then also perform Baseline RAG, otherwise skip this step |
| MaxChunks | the number of chunks to include with the Baseline RAG step |
As you can see there are several knobs to turn on this RAG application. From my testing, I’ve found the best results with these settings:
"PropertyGraph": {
// ...
"IncludeEntityTextSearch": true,
"TypeEntityTextOfSearch": "FULL_TEXT",
"UseKeywords": true,
"IncludeTriplets": true,
"MaxTriplets": 30,
"IncludeRelatedChunks": false,
"MaxRelatedChunks": 5,
"IncludeChunkVectorSearch": false,
"MaxChunks": 0
}
If you want to test a baseline RAG scenario, use these settings:
"PropertyGraph": {
// ...
"IncludeEntityTextSearch": false,
// ...
"IncludeChunkVectorSearch": true,
"MaxChunks": 5
}
In order to troubleshoot or see the triplets being added to the context, change line 47 in Program.cs to the following:
builder.SetMinimumLevel(LogLevel.Trace);
This will write a lot of detail out, and some of it will be the detail showing the triplets added to the context.
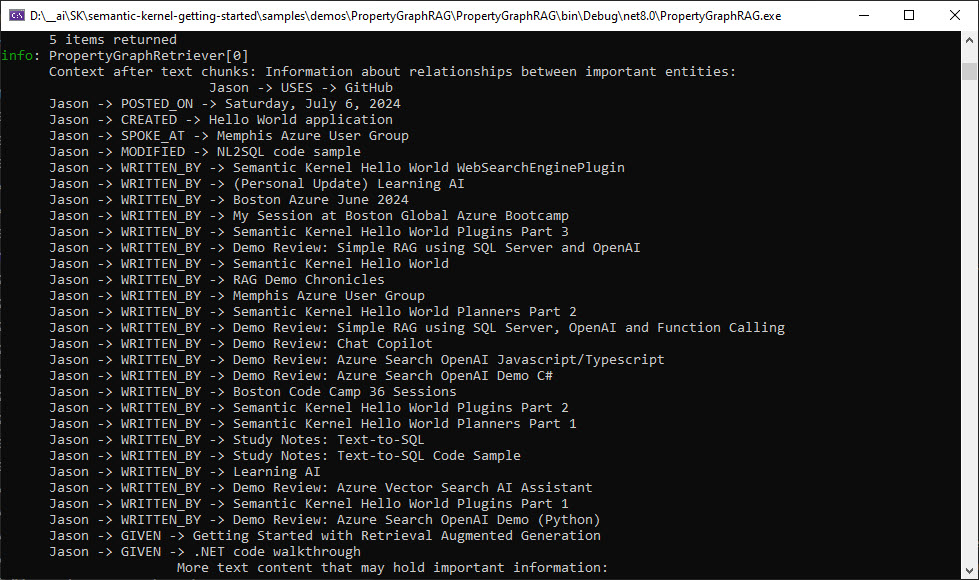
As shown above in A Quick Look at What It Does, the result can be much more accurate than baseline RAG. I’m going to continue to improve this solution and will update this blog entry once I make more progress.
I’ll leave it to you to play around with the retrieval and see what you think.
Conclusion
With these two console applications you should be able to start creating your own property graph RAG solution using Semantic Kernel.
The things you’ll need to do for your own data:
- test -> modify -> test the ExtractEntities prompt to create quality nodes and relationships needed for your data
- turn on the tracing and see how the vector vs. full text search is working for your
- test -> modify -> test the ReqeustWithContext prompt to get the most value out of the structured context being added by the property graph
One of the next things I’m working on to improve the value of using a property grid is Text-to-Cypher (coming soon).
If you have a comment, please message me @haleyjason on twitter/X.