Yesterday I posted my notes from this week’s study topic of Text-to-SQL, which if you haven’t read it - provides more information and resources about the topic. In this entry I want to walk through a code sample I put together after playing with a few samples this week.
Where To Get The Code
The code for this entry is in my GitHub repo semantic-kernel-getting-started under the samples/demos/Text-to-Sql directory.
Originally I considered making this a review of the NL2SQL code sample, but I ended up needing to make some changes to it, so I just copied over some of their code for my sample - that is why the nl2sql.library project is there (also there is a Nl2Sql folder in the TextToSqlConsole project with some other files from their repo). If you are looking into Text-to-SQL, I highly recommend taking a look at their sample.
Another important resource for my sample was Alex Wolf’s sample code https://github.com/alex-wolf-ps/dbchatpro. For my sample purposes, I ended up using the way he captured the results from the SQL execution so I could factor the code differently than the NL2SQL project.
A Quick Look at What It Does
What it looks like when connected to the AdventureWorks database:
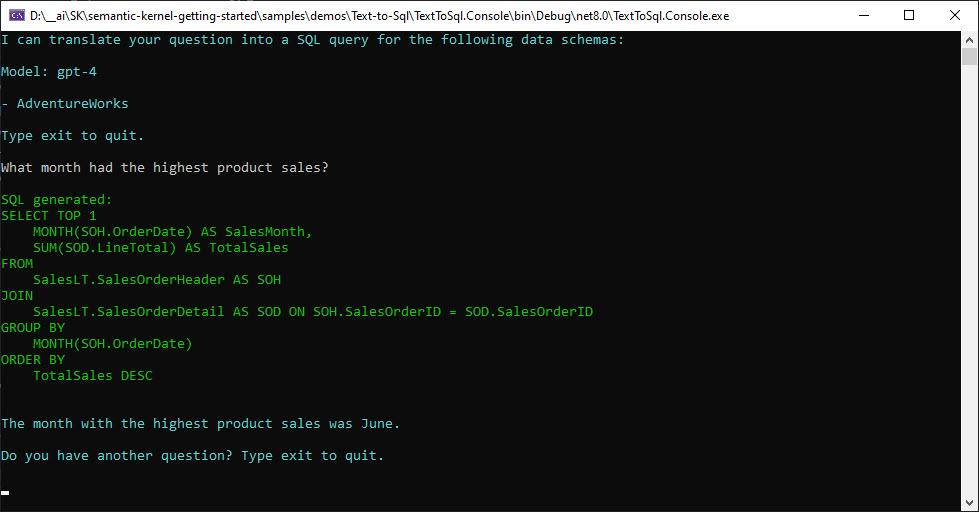
The idea is, you type in a question for the data in the database and it takes these steps in the code:
- Looks at the db schemas it has cached to see if the question is semantically similar to one of the schemas, if it isn’t then it states it can’t help.
- If a schema is found, then a few-shot prompt is put together and sent to the LLM to generate the SQL.
- The generated SQL is output to the console.
- The SQL is executed and the results captured in a simple string list structure.
- If there is more than a single row in the results, it outputs the data and then creates a prompt and passes the top 10 rows to the LLM to get a natural language response describing what is in the data. (I’m still playing with this prompt to see how useful I can get it).
- If there is only a single row in the results (ie. any query with TOP 1), it puts a prompt together and asks the LLM to create a nice natural language response to the user question with the data results.
- The final result from LLM is output to the UI
NOTE: There is no authorization or protection from destructive SQL execution currently. It is for demo purposes only.
There is one other path through the code, for instance if I ask “What columns are in the Product table”:
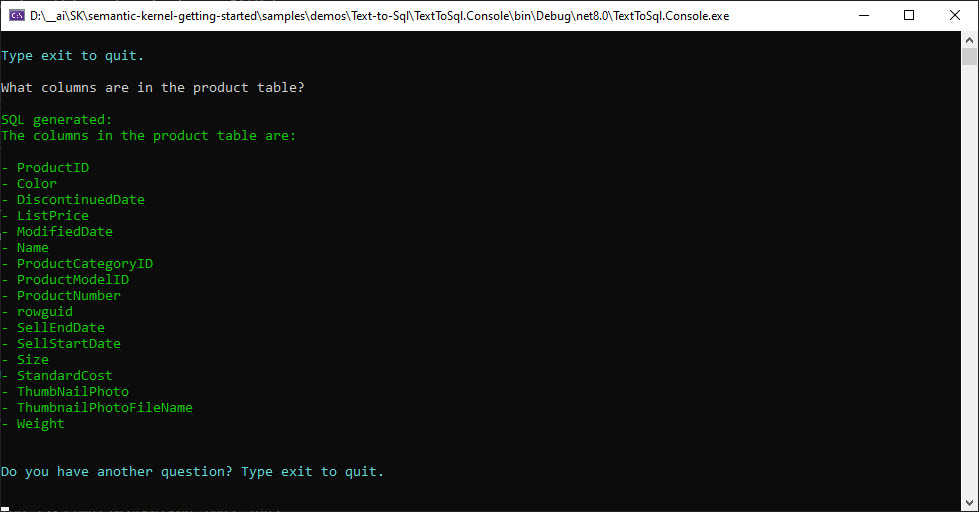
In this case only steps 1, 2 and 3 above are taken and instead of generated SQL, the LLM just answered the question with the passed schema.
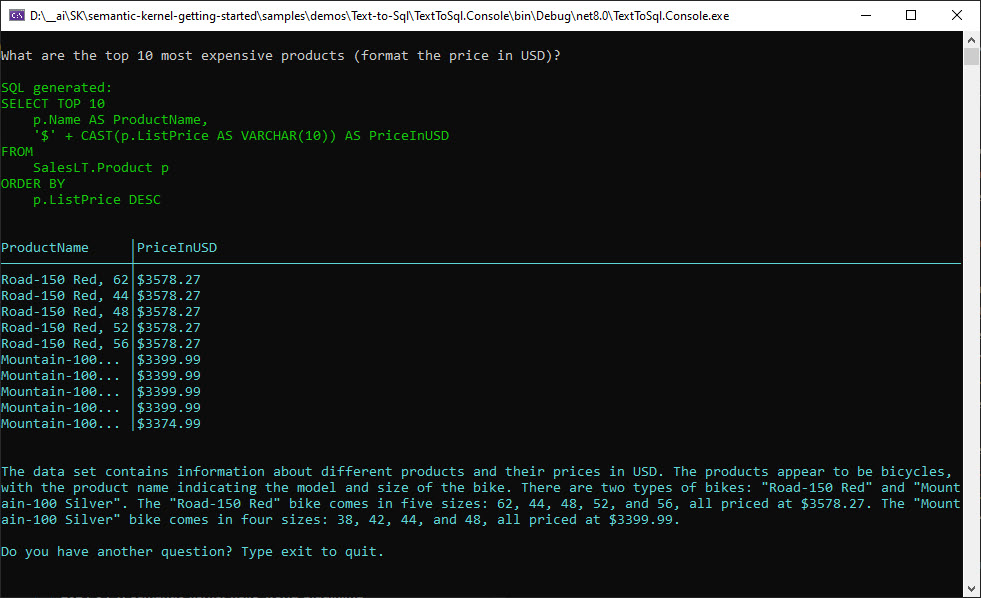
For completeness, here is a look at a question that returns the data rows then a description of the results:
The Code
Ignoring the displaying of the results, there are three phases for this application:
- Getting the schema
- The call to the LLM to generate the SQL (this is the Text-to-SQL phase)
- Execution of the SQL
If you have followed any of the Semantic Kernel Hello World blogs that I’ve written, you’ll notice the top of the Program.cs file is pretty similar (except for the color constants at the top):
using Microsoft.Extensions.Configuration;
using Microsoft.SemanticKernel;
using Microsoft.Extensions.Logging;
using Microsoft.Extensions.DependencyInjection;
using TextToSql.Console.Configuration;
using TextToSql.Console.Nl2Sql;
using Microsoft.SemanticKernel.Embeddings;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Services;
using SemanticKernel.Data.Nl2Sql.Library;
using System.Data;
internal class Program
{
private const ConsoleColor ErrorColor = ConsoleColor.Magenta;
private const ConsoleColor FocusColor = ConsoleColor.Yellow;
private const ConsoleColor QueryColor = ConsoleColor.Green;
private const ConsoleColor SystemColor = ConsoleColor.Cyan;
static void Main(string[] args)
{
MainAsync(args).Wait();
}
static async Task MainAsync(string[] args)
{
var config = Configuration.ConfigureAppSettings();
// Get Settings (all this is just so I don't have hard coded config settings here)
var openAiSettings = new OpenAIOptions();
config.GetSection(OpenAIOptions.OpenAI).Bind(openAiSettings);
using var loggerFactory = LoggerFactory.Create(builder =>
{
//builder.SetMinimumLevel(LogLevel.Information);
//builder.AddConfiguration(config);
//builder.AddConsole();
});
// Configure Semantic Kernel
var builder = Kernel.CreateBuilder();
builder.Services.AddSingleton(loggerFactory);
builder.AddChatCompletionService(openAiSettings);
//builder.AddChatCompletionService(openAiSettings, ApiLoggingLevel.ResponseAndRequest); // use this line to see the JSON between SK and OpenAI
builder.AddTextEmbeddingGeneration(openAiSettings);
//builder.AddTextEmbeddingGeneration(openAiSettings, ApiLoggingLevel.ResponseAndRequest);// use this line to see the JSON between SK and OpenAI
var kernel = builder.Build();
....
At this point, I have the majority of the logging commented out in order to cut down on the clutter when using the application for a demo. You may want to uncomment some of the lines to see more of the messaging.
Getting the Schema
My sample uses the schema generation code from NL2SQL, I just refactored it a bit so the connection strings could go in the appsettings.json file and be extendable for multiple database connections.
My appsetting.json file has the following three sections needed for the schema reading.
"TextToSql": {
"SchemaNames": "AdventureWorks", // comma delimited list
"MinSchemaRelevance": 0.7
},
"AdventureWorks": {
"ConnectionName": "AdventureWorksDb",
"Description": "Product, sales, and customer data for the AdentureWorks company."
//"Tables": "SalesLT.Customer,SalesLT.Address" // commented out or otherwise comma delimited list of tables including schema (ie. dbo.Users)
},
"ConnectionStrings": {
"AdventureWorks": "your-database-connection-string"
}
Important Sections in appsettings.json
TextToSql - this section has the comma delimited listing of SchemaNames and then a default setting for the MinSchemaRelevance factor (this is the semantic matching on the schema vs the user question - I ended up lowering it in the code to 0.5).
AdventureWorks - this section has to map to a name in the TextToSQL::SchemaNames comma delimited list of names. It has a name for the connection, description and an optional list of table names. This list of table names can be used to limit which tables in the database you want to pass to the LLM. If it is commented out, then it will grab all tables.
NOTE: If you want to add multiple databases for the application, then you need to add additional names in the TextToSql::SchemaNames and then create a section with that name (which needs to have the ConnectionName, Description and optionally Tables).
ConnectionStrings - this is where all the connection strings are stored for the application. Each connection string key needs to match a name in the TextToSql::SchemaNames section.
Schema Loading
In the Program.cs file, the text embedding service is retrieved from the kernel. Since I haven’t needed a text embedding service in the Semantic Kernel blog entries, I had to add a couple of keys to the OpenAI section in the the appsetting.json file for TextEmbeddingsModelId and TextEmbeddingsDeploymentName:
"OpenAI": {
"Source": "OpenAI", // or "AzureOpenAI"
"ChatModelId": "gpt-4",
"TextEmbeddingsModelId": "text-embedding-ada-002",
"ApiKey": "your-api-key",
"ChatDeploymentName": "gpt4",
"TextEmbeddingsDeploymentName": "text-embedding-ada-002",
"Endpoint": "your-azure-endpoint"
},
As mentioned above there is a step that checks for a schema that is semantically similar to the user’s question - for this we need to use the ITextEmbeddingGenerationService and currently it uses an in memory VolatileMemoryStore for holding the schemas and embeddings. Those are all instantiated in the Program.cs
var embeddingService = kernel.GetRequiredService<ITextEmbeddingGenerationService>();
var memoryBuilder = new MemoryBuilder();
memoryBuilder.WithTextEmbeddingGeneration(embeddingService);
memoryBuilder.WithMemoryStore(new VolatileMemoryStore());
var memory = memoryBuilder.Build();
var schemaLoader = new SqlScemaLoader(config);
if (!await schemaLoader.TryLoadAsync(memory).ConfigureAwait(false))
{
WriteLine(ErrorColor, "Unable to load schema files");
}
WriteIntroduction(kernel, schemaLoader.SchemaNames);
The SchemaLoader takes the IConfiguration object in the constructor in order to read in all the necessary sections of the appsetting.json file.
private readonly IConfiguration _configuration;
private TextToSqlOptions _textToSqlOptions = new TextToSqlOptions();
private readonly Dictionary<string, SqlSchemaOptions> _sqlSchemaOptionsMap = new Dictionary<string, SqlSchemaOptions>();
public SqlScemaLoader(IConfiguration confuration)
{
_configuration = confuration;
Initialize();
}
public IList<string> SchemaNames { get { return _textToSqlOptions.SchemaNames.Split(','); } }
public double MinSchemaRelevance { get { return _textToSqlOptions.MinSchemaRelevance; } }
private void Initialize()
{
_configuration.GetSection(TextToSqlOptions.TextToSqlConfig).Bind(_textToSqlOptions);
if (!string.IsNullOrEmpty(_textToSqlOptions.SchemaNames))
{
foreach (var name in SchemaNames)
{
var schema = new SqlSchemaOptions();
_configuration.GetSection(name).Bind(schema);
_sqlSchemaOptionsMap.Add(name, schema);
}
}
}
The SchemaLoader.TryLoadAsync() is where the database connection is made and the schemas are parsed and cached in a json file then loaded in memory. It aslo checks if the json file already exists and loads it if it does.
public async Task<bool> TryLoadAsync(ISemanticTextMemory memory)
{
if (!HasSchemas())
{
System.Console.WriteLine("No schemas configured in appsettings.json");
return false;
}
foreach (var schema in _sqlSchemaOptionsMap.Keys)
{
if (!SchemeFileExists(schema))
{
await CreateSchemaFileAsync(schema, _sqlSchemaOptionsMap[schema]);
}
}
await SchemaProvider.InitializeAsync(memory, _sqlSchemaOptionsMap.Keys.Select(s => $"{s}.json")).ConfigureAwait(false);
return true;
}
The database is actually connected to in the SchemaLoader.CreateSchemaFileAsync(), which I leave to you to look at if you are interested.
NOTE: Since the connection string in the appsettings.json file is used for the creation of the schema file, you will only get the tables that the user in the connection string has access to. This is one location you could narrow down what schema information is going to be passed to the LLM.
Calling the LLM to Generate SQL
Once the schema(s) have been loaded in memory, the code goes into a loop for the user interaction. I’m going to ignore the console writing and application interaction and focus on the core functionality here.
var queryGenerator = new SqlQueryGenerator(kernel, memory, 0.5);
The SqlQueryGenerator takes the kernel, memory and a relevance factor for the schema matching. I started with the NL2SQL implementation of SqlQueryGenerator, but modified it a bit. The first thing was to move the prompts from xml files to the directory type prompts, which now get loaded in the constructor:
public SqlQueryGenerator(
Kernel kernel,
ISemanticTextMemory memory,
double minRelevanceScore = DefaultMinRelevance)
{
var prompts = kernel.CreatePluginFromPromptDirectory("Prompts");
this._promptEval = prompts["EvaluateIntent"];
this._promptGenerator = prompts["SqlGenerate"];
this._promptResultEval = prompts["EvaluateResult"];
this._promptDescribeResults = prompts["DescribeResults"];
this._kernel = kernel;
this._memory = memory;
this._minRelevanceScore = minRelevanceScore;
}
Currently there are four prompts in the application:
| Name | Description |
|---|---|
| DescribeResults | (Sort of experimental) Used to describe the top 10 rows of a query’s results |
| EvaluateIntent | Determines if the user request is related to the described schema |
| EvaluateResult | Answers the user question for the given SQL query and results |
| SqlGenerate | Creates valid SQL for a given user request |
The SqlQueryGenerator.SolveObjectiveAsync() will end up using two of those prompts if there is a schema that matches the user’s question.
var result = await queryGenerator.SolveObjectiveAsync(userInput).ConfigureAwait(false);
The first thing this method does is search the memory store for a related schema. If a schema is not found to be related enough, then null is returned and its done. Otherwise, the schema’s text (formatted as yaml) and user’s question are used to construct the EvaluateIntent prompt and passed to the LLM in the ScreenObjectiveAsync method.
public async Task<SqlQueryResult?> SolveObjectiveAsync(string objective)
{
// Search for schema with best similarity match to the objective
var recall =
await this._memory.SearchAsync(
SchemaProvider.MemoryCollectionName,
objective,
limit: 1, // Take top result with maximum relevance (> minRelevanceScore)
minRelevanceScore: this._minRelevanceScore,
withEmbeddings: true).ToArrayAsync().ConfigureAwait(false);
var best = recall.FirstOrDefault();
if (best == null)
{
return null; // No schema / no query
}
var schemaName = best.Metadata.Id;
var schemaText = best.Metadata.Text;
var arguments = new KernelArguments();
arguments[ContextParamSchema] = schemaText;
arguments[ContextParamObjective] = objective;
// Screen objective to determine if it can be solved with the selected schema.
if (!await this.ScreenObjectiveAsync(arguments).ConfigureAwait(false))
{
return null; // Objective doesn't pass screen
}
var sqlPlatform = best.Metadata.AdditionalMetadata;
arguments[ContextParamPlatform] = sqlPlatform;
// Generate query
var result = await this._promptGenerator.InvokeAsync(this._kernel, arguments).ConfigureAwait(false);
// Parse result to handle
string query = result.ParseValue(ContentLabelQuery);
return new SqlQueryResult(schemaName, query);
}
The EvaluateIntent prompt asks the LLM if the user’s request is related (or can be solved) with the provided schema. The result should be YES or NO coming back from the LLM.
If the ScreenObjective returns false, then the method is done an no SQL is generated. Otherwise the SQLGenerate prompt is called with the type of SQL being requested, the schema and the user’s question.
NOTE: This is the Text-to-SQL part of the system.
<message role="system">
Generate a SQL SELECT query that is compatible with {{$data_platform}}, use aliases for all tables and reference those aliases when used and achieves the OBJECTIVE exclusively using only the tables and views described in "SCHEMA:".
Only generate SQL if the OBJECTIVE can be answered by querying a database with tables described in SCHEMA.
</message>
<message role="system">
Respond with only with valid SQL
</message>
<message role="user">
SCHEMA:
description: historical record of concerts, stadiums and singers
tables:
- stadium:
columns:
Stadium_ID:
Location:
Name:
Capacity:
Highest:
Lowest:
Average:
- singer:
columns:
Singer_ID:
Name:
Country:
Song_Name:
Song_release_year:
Age:
Is_male:
- concert:
columns:
concert_ID:
concert_Name:
Theme:
Stadium_ID:
Year:
- singer_in_concert:
columns:
concert_ID:
Singer_ID:
references:
concert.Stadium_ID: stadium.Stadium_ID
references:
singer_in_concert.concert_ID: concert.concert_ID
singer_in_concert.Singer_ID: singer.Singer_ID
OBJECTIVE: How many heads of the departments are older than 56 ?
</message>
<message role="assistant">
select count(*) department_head_count from head where age > 56
</message>
<message role="user">
SCHEMA:
{{$data_schema}}
OBJECTIVE: {{$data_objective}}
</message>
Once the SqlQueryGenerator.SolveObjectiveAsync() returns to the Program.cs, it will be null (the couple of cases mentioned earlier when no related schema is found or the LLM says the request doesn’t match the schema contents enough) or it will have the Query property populated.
The Query property is then written to the console. This may be a SQL statement or it could just be a column listing or some other answer the LLM provided from the previous prompt - so it may not need to go to the next step.
Executing the SQL
At this point the Text-to-SQL has been completed. Now that we have a SQL query, we want to run it.
NOTE: This is where in the non demo type setup you will want to add permissioning and some checks to make sure the user can’t do anything to the database that you don’t want them to.
The SqlCommandExecutor is where the execution takes place, so it needs the correct connection string passed to its constructor.
var sqlExecutor = new SqlCommandExecutor(schemaLoader.GetConnectionString(result.Schema));
var dataResult = await sqlExecutor.ExecuteAsync(result.Query);
There isn’t any exciting stuff going on in the SqlCommandExecutor.ExecuteAsync(), it uses a SqlConnection and SqlCommand to run the SQL and then loops through the SqlDataReader to create a list of strings to output to the console.
If the passed in SQL doesn’t have SELECT in the text, then it returns an empty list - this is exercised in the example earlier when the LLM returned a list of column names.
public async Task<List<List<string>>> ExecuteAsync(string sql)
{
if (sql.IndexOf("SELECT") == -1)
{
return new List<List<string>>();
}
var rows = new List<List<string>>();
try
{
using (var connection = new SqlConnection(_connectionString))
{
await connection.OpenAsync();
using var command = connection.CreateCommand();
#pragma warning disable CA2100 // Review SQL queries for security vulnerabilities
command.CommandText = sql;
#pragma warning restore CA2100 // Review SQL queries for security vulnerabilities
using var reader = await command.ExecuteReaderAsync();
bool headersAdded = false;
while (reader.Read())
{
var cols = new List<string>();
var headerCols = new List<string>();
if (!headersAdded)
{
for (int i = 0; i < reader.FieldCount; i++)
{
headerCols.Add(reader.GetName(i).ToString());
}
headersAdded = true;
rows.Add(headerCols);
}
for (int i = 0; i <= reader.FieldCount - 1; i++)
{
try
{
cols.Add(reader.GetValue(i).ToString());
}
catch
{
cols.Add("DataTypeConversionError");
}
}
rows.Add(cols);
}
}
}
catch
{
throw;
}
return rows;
}
Once the results are returned, I currently have a couple of additional calls to the LLM to provide descriptions of the results. At the moment, I’m not sure they make sense but they do help it make a nice demo. However, since the focus really was on how to do Text-to-SQL, I’ll leave it to you to investigate the code and determine if those additional calls are of any value to you.
Conclusion
In this entry, I showed how to implement Text-to-SQL using Semantic Kernel, SQL Server and Open AI GPT 4. In my experience playing with GPT 4, I found it pretty good at creating SQL.
In case you start to have problems with your generated SQL, this blog: AI SQL Accuracy: Testing different LLMs + context strategies to maximize SQL generation accuracy mentions some tips on how to increase the accuracy of Text-to-SQL. One thing that may be valuable is to save queries as they are generated (and successfully run) along with the user request, in order to add those to similar user requests in the future. To do so with this sample code wouldn’t be too big of a change, but I’ll leave that to you for now.
If you have a comment, please message me @haleyjason on twitter/X.