Demo Review: Azure Search OpenAI Demo C#
If you are looking for Retrieval Augmented Generation (RAG) demos that utilize Azure Search and Azure OpenAI (along with several other supporting Azure services), then there is a set of related demos that do just that in GitHub.
This family of RAG demos consists of:
- azure-search-openai-demo-csharp - written in C#.
- azure-search-openai-demo - written in python.
- azure-search-openai-javascript - written in javascript/typescript.
- azure-search-openai-demo-java - written in java.
This post is about #1 above, I will cover #2 and #3 in later posts, but I will leave the Java version to someone else to review.
Before digging into this family of demos, it is important to note they are not the same functionality ported to different languages. The thing they have in common is the usage of Azure Search, Azure OpenAI and the UI look and feel is similar but that is about it.
The previous demos (#1 and #2) were good starting points to learn what the RAG pattern is about, this demo takes you a few steps closer to what is needed for a production implementation.
Demo Details
| Item of Interest | As of 2/13/2024 |
|---|---|
| Author: | 24 Contributors |
| Date created: | 4/2/2023 |
| Update within last month: | Yes |
| Link to documentation: | Project’s Readme |
| Github project link: | https://github.com/Azure-Samples/azure-search-openai-demo-csharp |
| Watching: | 38 |
| Forks: | 232 |
| Stars: | 403 |
| Knowledge needed to use: | C# Azure services |
| Prerequisites to get demo working: | Azure account Access to Azure OpenAI (apply here) Git (if you follow my instructions) AZD (Azure Developer CLI) (if following my instructions below) Docker Desktop (if following my instructions below) |
| Knowledge would be helpful but not required: | Blazor WASM MudBlazor Blazor.LocalStorage Blazor.SessionStorage Blazor.SpeechRecognition Blazor.SpeechSynthesis Azure services below Open AI APIs |
| Technologies Used: | ASP.NET 8 C# Blazor Minimal APIs Azure Key Vault Azure Container Apps Azure Container Registry Azure AI Document Intelligence (aka Form Recognizer) Azure OpenAI Azure Functions Azure Storage Azure AI Search (aka Azure Search and Azure Cognitive Search) Semantic Kernel |
Demo Description
I considered breaking this demo review up into two parts since there is so many good details I’d like to mention … but I decided to focus more on the highlights and not try and cover all the details.
A look at the User Interface (UI)
Like the previous demos, the UI is written in Blazor (though this is WASM and the others were Server). When the application loads (/Pages/Index.razor), you see a slide show of images generated from DALL-E - however these are not being generated on the fly (they are committed to source control). If you look at the network traffic you’ll see a failed api call to “api/images”, which seems to be mostly ready to get images from a DALL-E deployment, however doing so in Azure OpenAI is tricky right now since it is only in preview in two regions. In the near future you should be able to wire this up - but just not now. One useful feature on the top toolbar is the moon button that toggles the theme from light theme to dark theme - I’ve had customers ask for this sort of thing - so really nice to see in a demo.
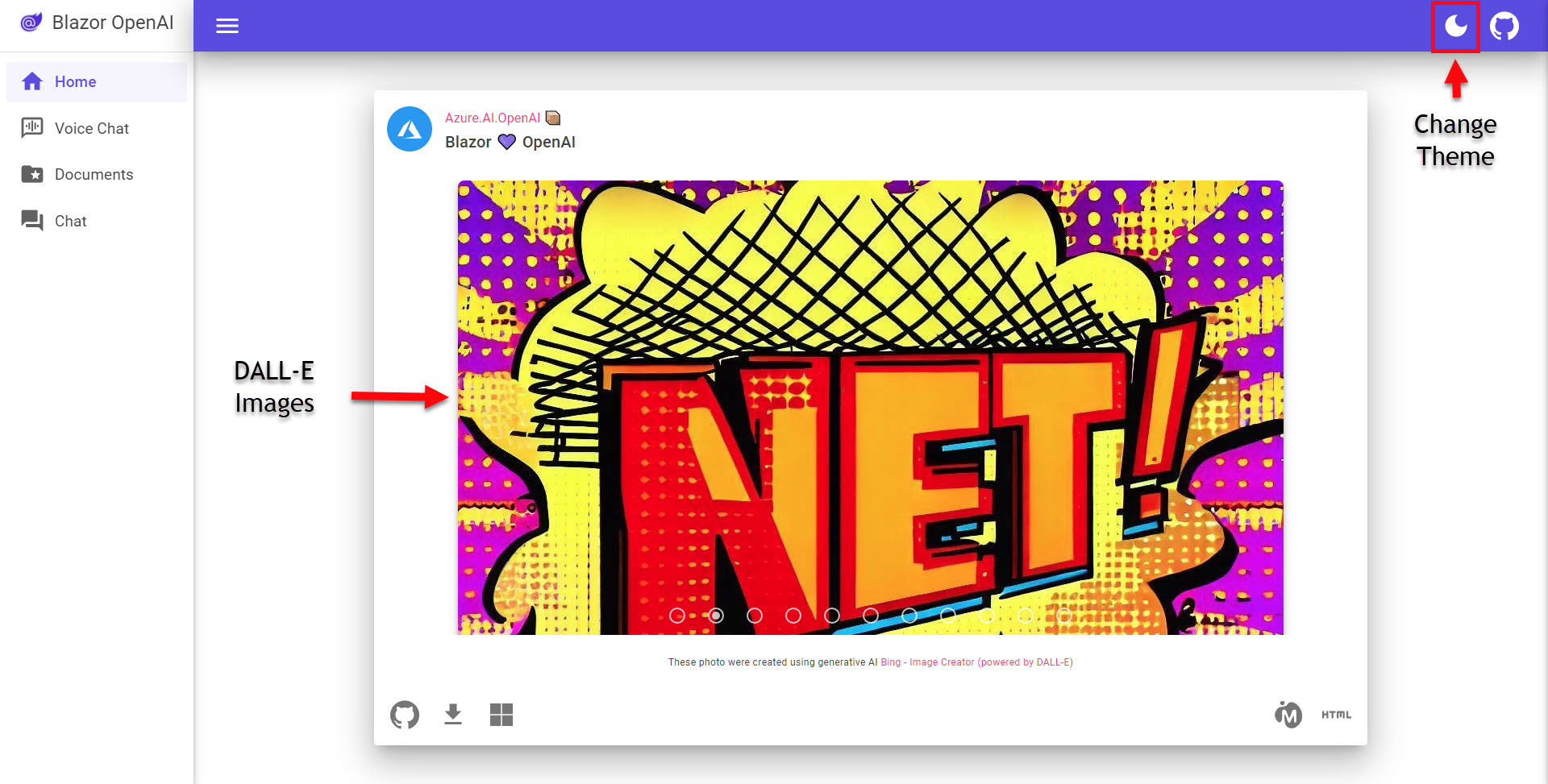
On the Voice Chat page (/Pages/VoiceChat.razor), you have the implementation of using the browser’s speech features to talk to the application and listen to the reply. I believe the functionality is provided by the browser (if you look at the network traffic and see the blazorators.speechRecognition.js and blazorators.speechSynthesis.g.js files you’ll see the javascript used to do this (these are provided by the Blazor.SpeechRecognition and Blazor.SpeechSynthesis packages in the UI project). So if you are looking for that sort of functionality in your application, this may be a good place to start. When you click the microphone button and start talking, the text will show in the prompt text box. When you click Stop, the Ask button will become enabled. You can also show the Text-to-speech Preferences dialog to choose a voice, the voice speed and enable/disable the feature for it to read the answer to you (or not). The stop button can be used to stop the audio playback.
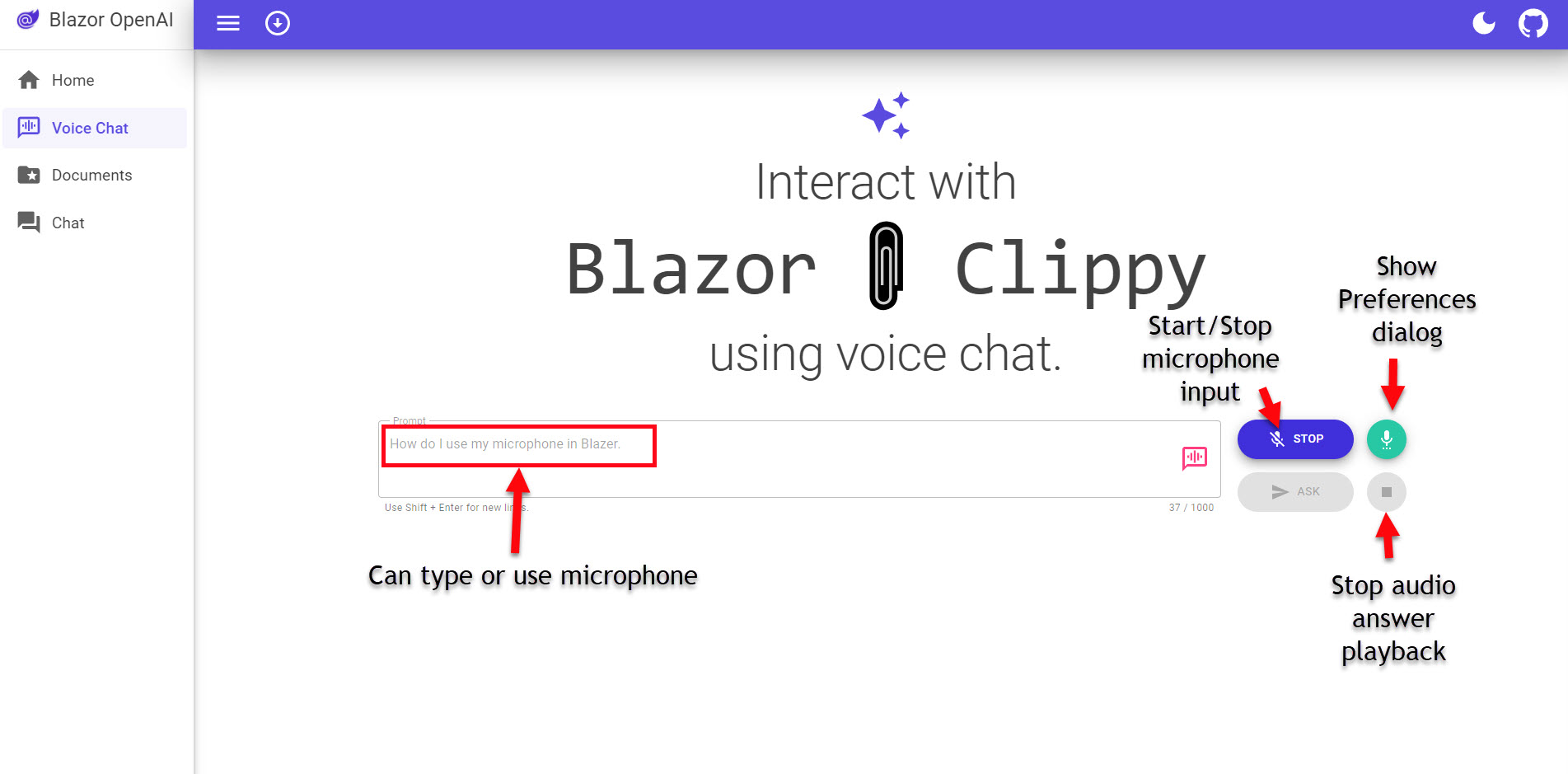
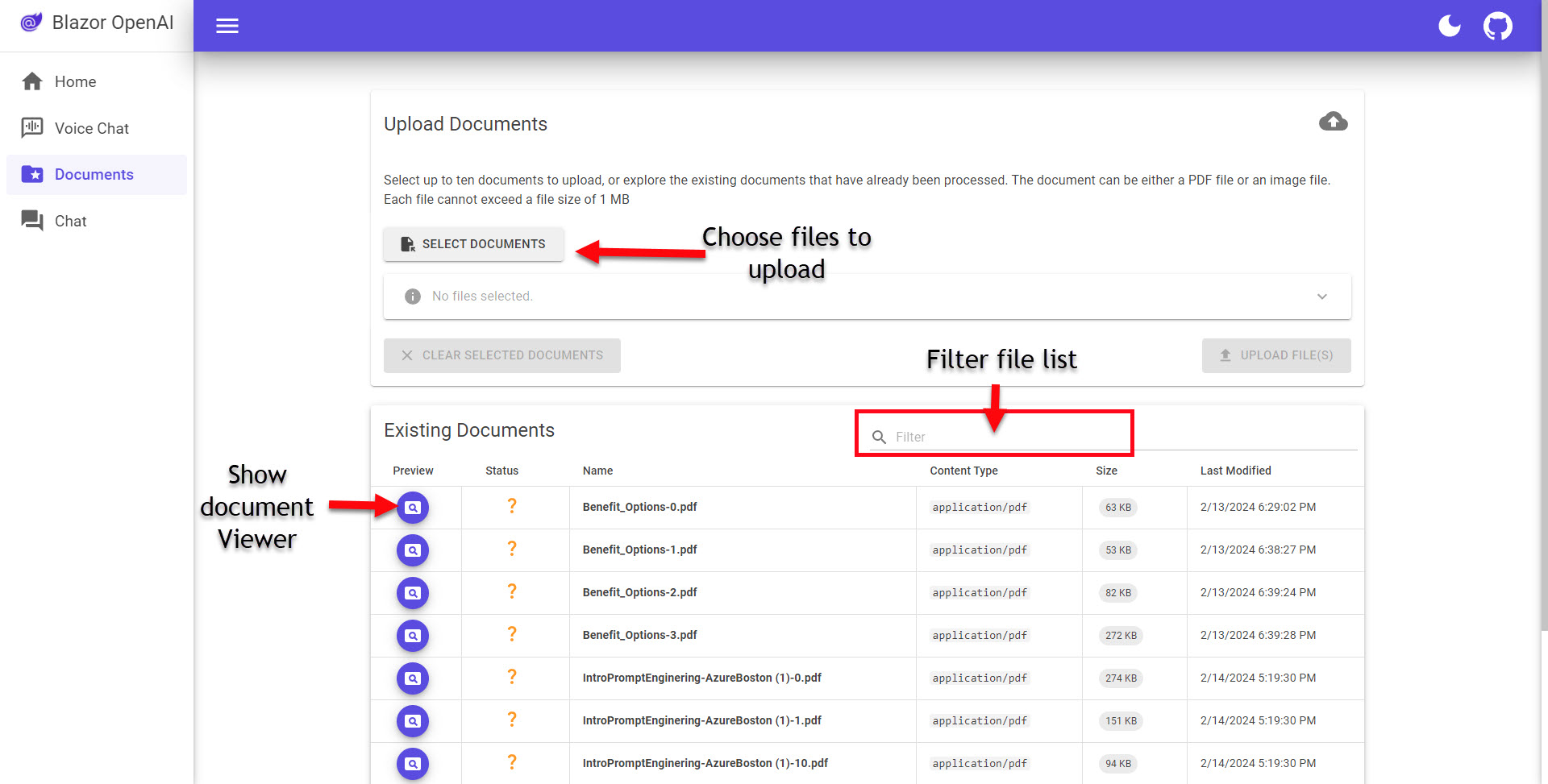
The Documents page (/Pages/Docs.razor), you see a paged file listing of what has been added to the search index. This page provides some useful functionality like: a show document viewer button that opens a dialog with the document in it, file information like name, content type, size and last modified date. There is also a typeahead filter box right above the table (very useful). At the top, there is a panel that provides the necessary controls for users to upload additional documents. Again, nice functionality and I can see these features being needed in a production application.
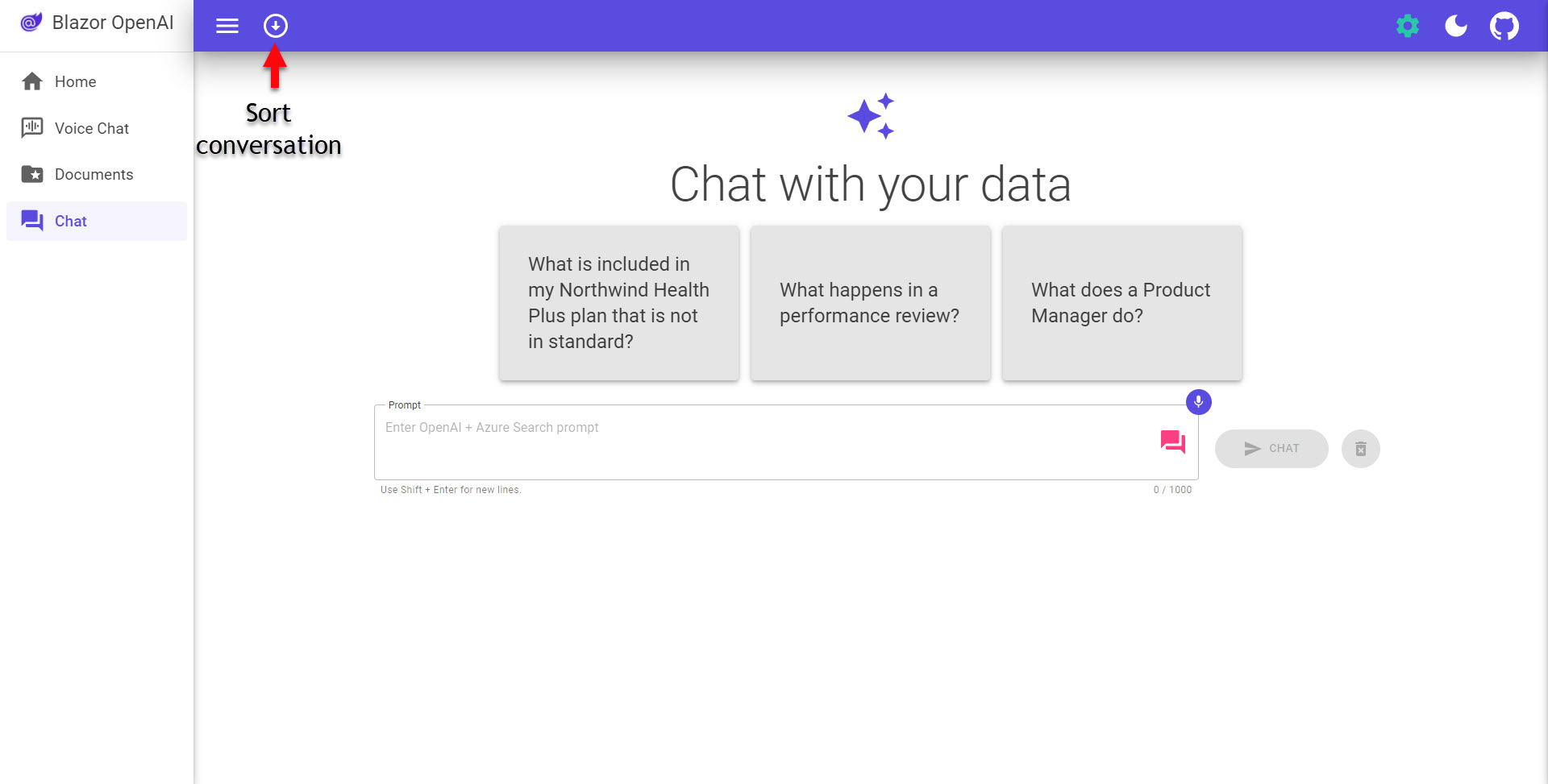
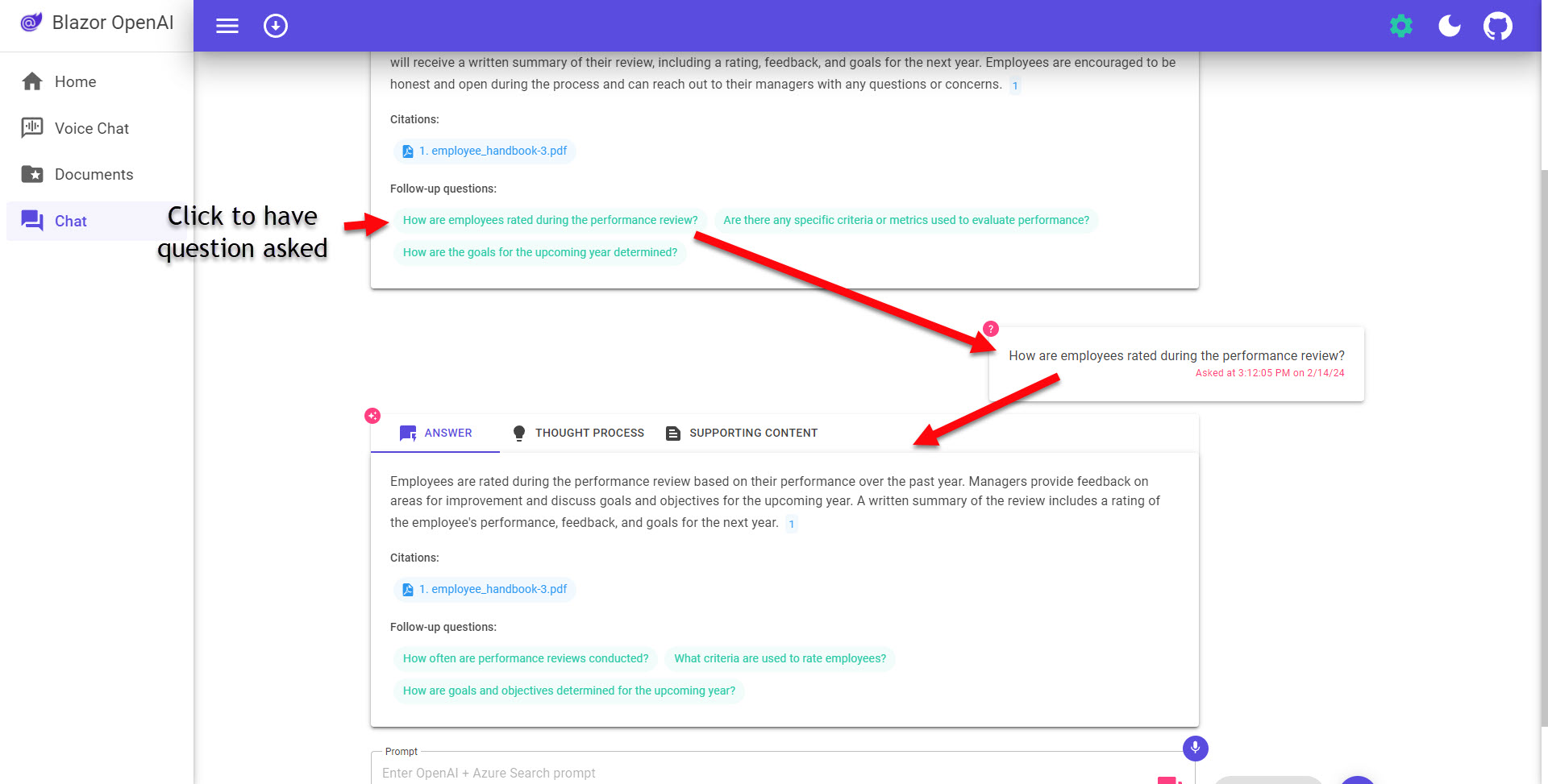
The Chat page (/Pages/Chat.razor), this is the chat interaction for the RAG demo. The sample questions are always a nice place to start to see how the system works (and if the whole system successfully deployed). Once you have some chat history going - the conversation sort button in the upper left is pretty useful if you like to have the most recent at the top.
Now the good stuff - the chat UI. This demo has several useful pieces to it (labeled in image below): tabs for the Answer, thought process and supporting content. Citations are super useful with RAG applications and the clickable link to open a dialog with the document is really useful too. The follow-up question links are also something I can see being useful in a production application.
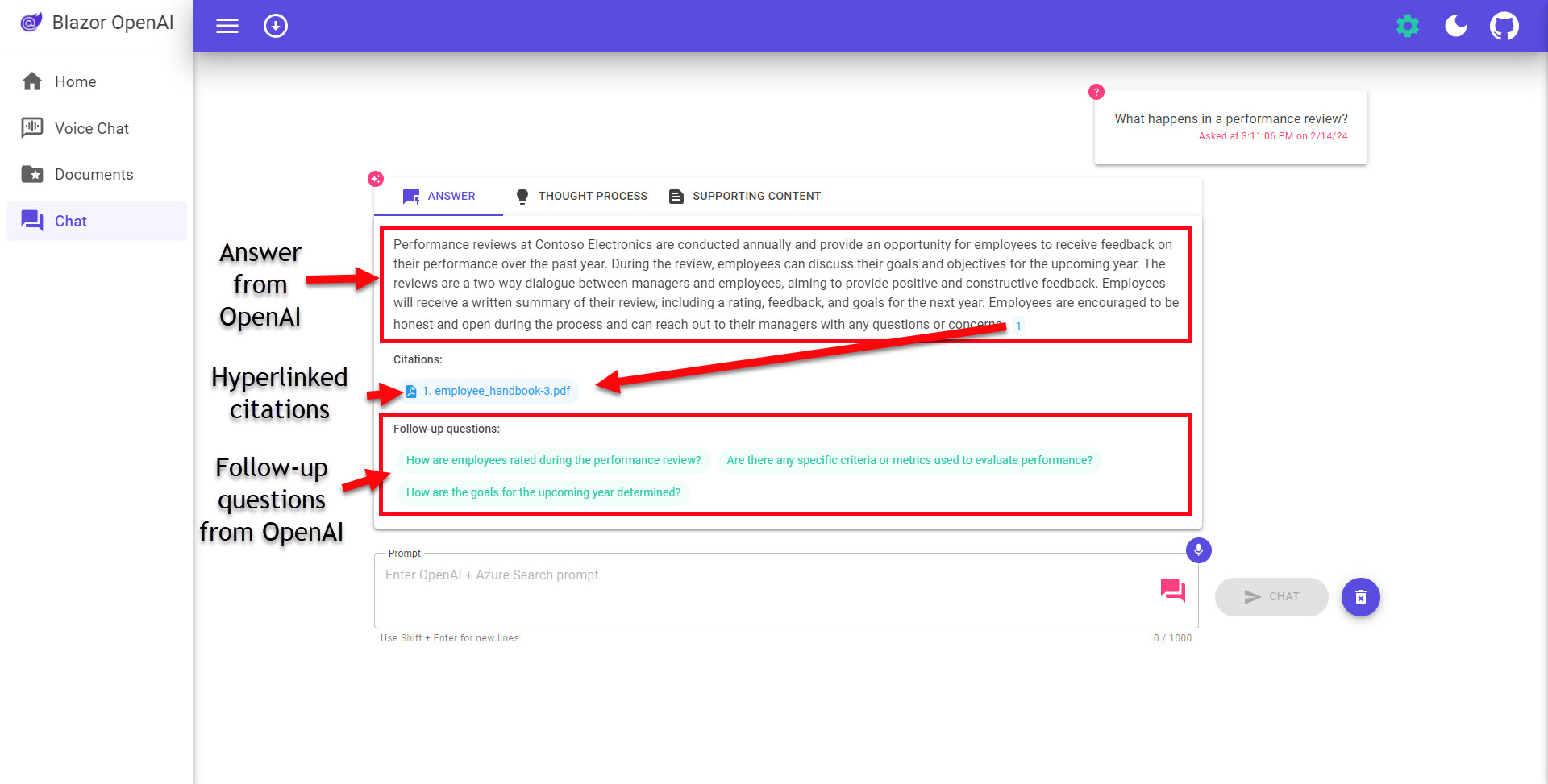
Thought process tab that explains how the answer was derived.

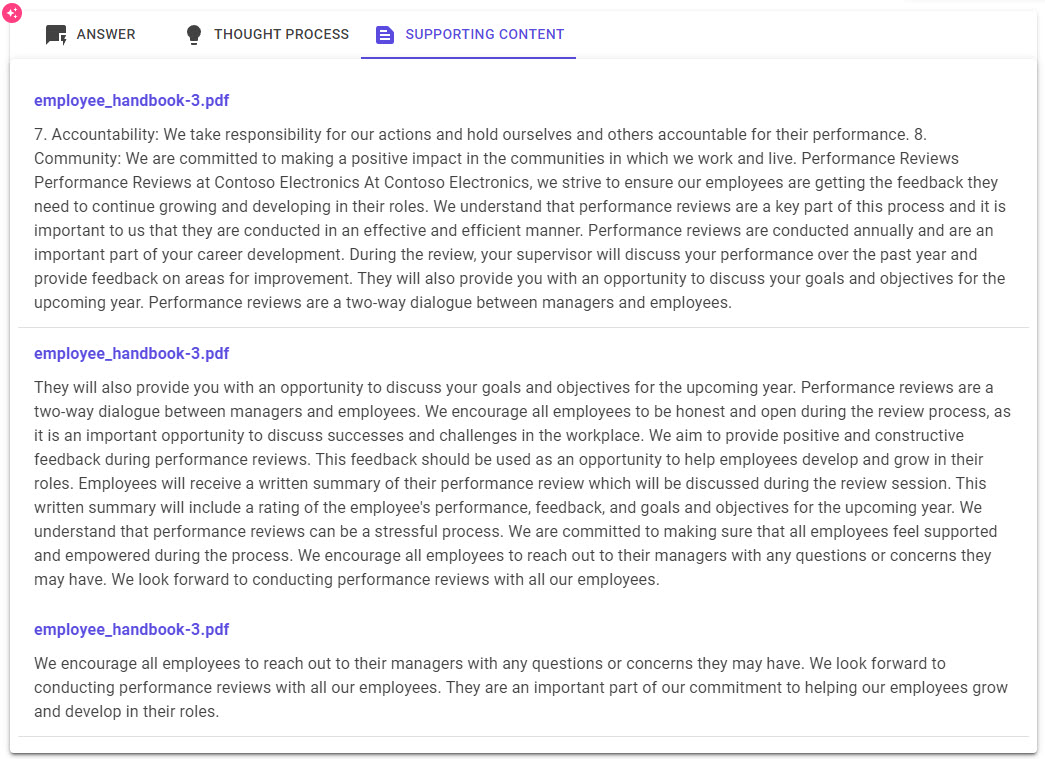
Supporting Content tab that shows the top 3 chunks of text the search found.
Click on a follow-up question to have it asked:
A look at the Backend
With the backend logic, there are really four classes that are the most interesting:
There is some logic in the application regarding vectorizing images and using ChatGPT vision, but it doesn’t seem like it is completely implemented yet (as of 2/14/2024).
AzureSearchEmbedService
This service is where the logic is for parsing pdf files, chunking them into smaller pdfs, driving of creating the search index, etc. I would start with the EmbedPDFBlobAsync() method, it is the main method. The GetDocumentTextAsync() method uses the Form Recognizer client to get the pdf parsed and returned as an array of pages. It also handles tables if there are any recognized in the pdf. The CreateSections() method is where the page text gets split into smaller chunks and pdfs (more on the chunking below). Once the pdfs are all split into smaller pieces and uploaded to blob strorage, then the IndexSectionsAsync() method takes the sections, gets their embeddings from OpenAI then adds their content and embeddings to the Azure Search index.
ReadRetreiveReadChatService
This service uses Semantic Kernel to provide the chat workflow with the Aure OpenAI API. The kernel setup is in the constructor of the service.
var endpoint = configuration["AzureOpenAiServiceEndpoint"];
ArgumentNullException.ThrowIfNullOrWhiteSpace(endpoint);
kernelBuilder = kernelBuilder.AddAzureOpenAITextEmbeddingGeneration(embeddingModelName, endpoint, tokenCredential ?? new DefaultAzureCredential());
kernelBuilder = kernelBuilder.AddAzureOpenAIChatCompletion(deployedModelName, endpoint, tokenCredential ?? new DefaultAzureCredential());
...
_kernel = kernelBuilder.Build();
The bulk of the service’s logic is the ReplyAsync() method, which drives the RAG pattern for the Chat page in the application. This method gets the embeddings for the user’s question, queries the search index, builds the prompt to send to OpenAI, if the setting is turned on for providing follow-up questions - it makes a second call to OpenAI to get those. Once it has all the content from search (plus urls for the related documents in blob storage), responses from OpenAI, it returns all the relevant data to the UI.
AzureSearchService
This service is used to query the search index. It takes in the user’s query chat message, embeddings from the user’s question, settings from the UI (like whether to use Semantic Search, Retrieval Mode, etc.), then handles the search client’s settings to make the call and returns records with the search score, id, content, category, sourcepage and sourcefile from the index search.
From the QueryDocumentsAsync() method:
// Assemble sources here.
// Example output for each SearchDocument:
// {
// "@search.score": 11.65396,
// "id": "Northwind_Standard_Benefits_Details_pdf-60",
// "content": "x-ray, lab, or imaging service, you will likely be responsible for paying a copayment or coinsurance. The exact ...",
// "category": null,
// "sourcepage": "Northwind_Standard_Benefits_Details-24.pdf",
// "sourcefile": "Northwind_Standard_Benefits_Details.pdf"
// }
AzureBlobStorageService
This is the blob uploading logic for the UI only. It uses PdfSharpCore to break the documents up into pages before uploading to blob storage.
NOTE: If the setting is normal pascal case (ie. UseAOAI) the value is coming from Azure Key Vault, if it is all upper case (ie. USE_AOAI) the value is coming from an environment variable.
How to get it up and running
NOTE: This is how I got it working today (2/14/2024), the repo is under active development - so there is a chance things have changed if you are reading this long after that.
Due to the application being deployed to an Azure Container App, a container will get built during the package phase this requires Docker Desktop to be running. If you don’t have it, you will need to install it.
The repository is designed to be built and deployed to Azure using the Azure Developer CLI (AZD), if you don’t have it installed you will need to install it. The AZD documentation is at: https://learn.microsoft.com/en-us/azure/developer/azure-developer-cli/reference
You will also need to be approved for the Azure OpenAI services on your Azure subscription before getting it up and running. Apply Here - it usually takes around 24 hours to get approved.
- Clone the repo to your local drive
- Start docker desktop (you will get an error like shown below if you don’t have it running when you get to the last step)

- Open VS Code and a PowerShell terminal (or open command line to demo’s root directory to run AZD)
- Delete the img directory in the data folder.
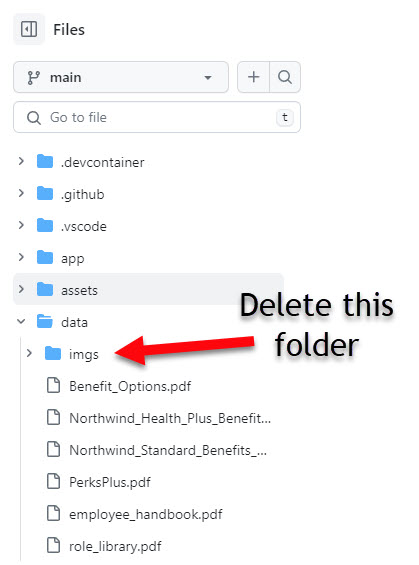
NOTE: This is due to work in progress - the Prepare Documents process that runs after the infrastructure is provisioned will fail if it finds image files. (This will change in the future and not be necessary but it is as of 2/14/2024 it is)
- Run
azd auth loginand login to your Azure subscription that is approved for Azure OpenAI. - Run
azd up
You will need to choose the subscription and location (eastus or eastus2 have been good for me).
Also due to the same image/computer vison work in progress mentioned above, you will need to answer the following questions as AZD works through its steps:
? Enter a value for the 'azureComputerVisionServiceEndpoint' infrastructure parameter: **Just hit ENTER here and leave blank**
? Save the value in the environment for future use Yes
? Enter a value for the 'openAIApiKey' infrastructure parameter: **Just hit ENTER here and leave blank**
? Save the value in the environment for future use Yes
? Enter a value for the 'useGpt4V' infrastructure parameter: False
? Save the value in the environment for future use Yes
The whole process has been taking around 15 minutes to deploy for me.
While the provisioning is taking place, you will get a link to the Azure Portal that will show you the statuses of the resources being deployed. Once it is complete, it will look something like this:
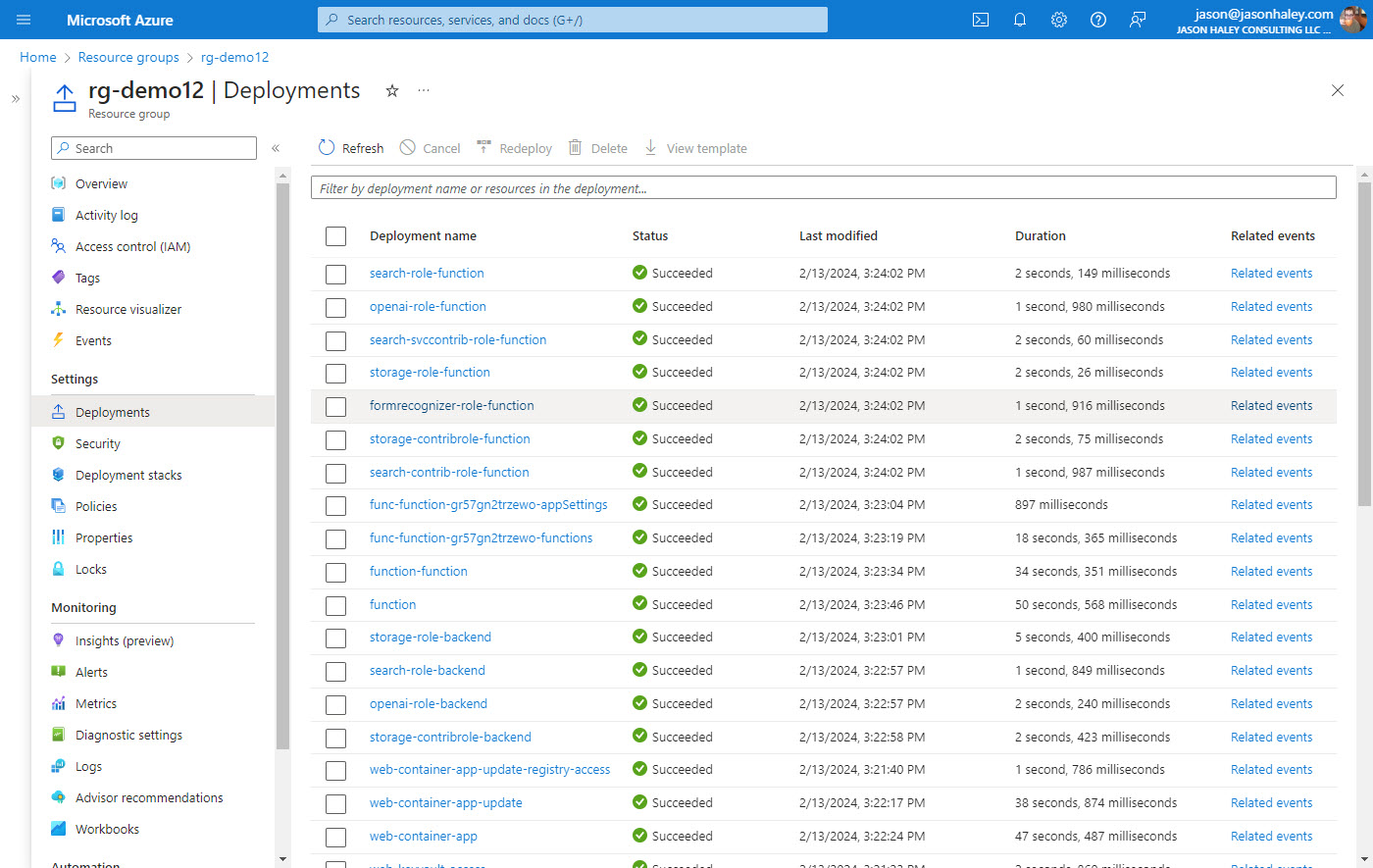
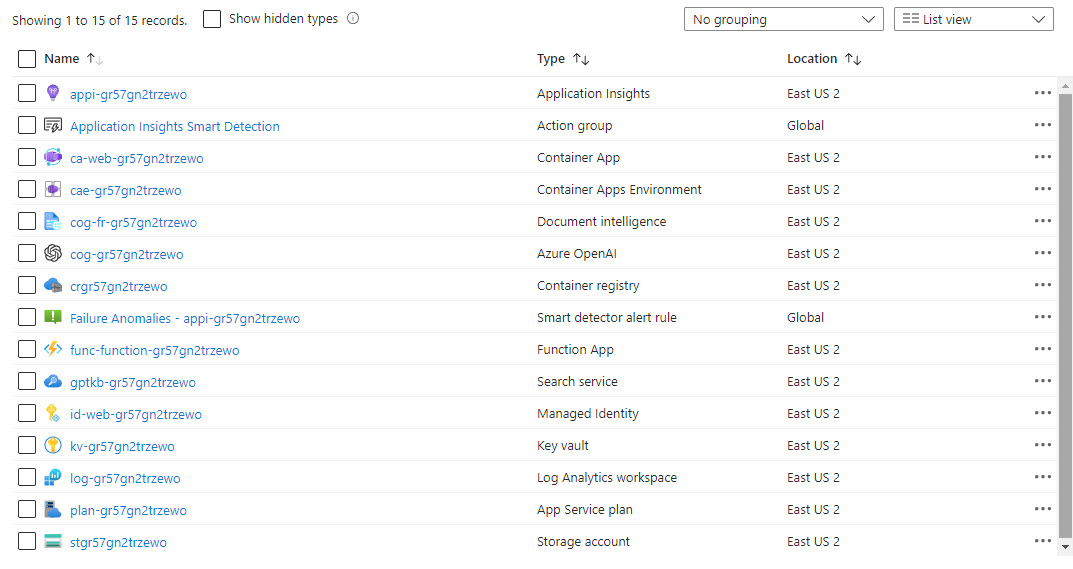
If you go to the resource group, you will see 15 resources deployed:
Once the deployment is complete, you should get a url in the console to a container app that looks something like this:
https://ca-web-gr57gn2trzewo.calmsea-98c202b9.eastus2.azurecontainerapps.io/
NOTE: Do not forget these will be costing money
In order to remove everything, the best way is to run azd down it will remove all resources and ask you to verify final deletion. You can delete the resource group but Azure Key Vault, Azure OpenAI and Azure AI Document Intelligence all do a soft delete when you do that, so if you want to purge those resources you will need to manually do it - this is why azd down is better and does take some time.
Points of Interest
These are some items in the demo that are RAG feature related and you may revisit later when you start creating your own RAG applications.
Storing vector embeddings in Azure AI Search
This demo uses Azure AI Search for storing the vector embeddings, content to be indexed, metadata about that content, perform a similarity search on the index, optionally perform a semantic search, filter by category, etc. The logic that does all this is in the AzureSearchService.QueryDocumentsAsync() method. So if you want to use Azure AI Search in your application, this service is a good place to start.
Do pay attention to the pricing, it is not a cheap solution if you turn on all the features.
Use of Azure AI Document Intelligence to parse PDF files
Azure AI Document Intelligence is used for parsing pdf files - this is an important feature in order to get the chunk size of your documents down to have more relevant vector embeddings. This demo uses it to parse the pdf pages as well as tables. The latest version’s Layout model also supports office and html files.
Chunking technique
The chunking technique in this demo is more advanced than the one in demos (#1 and #2. The chunking is done in the AzureSearchEmbedService.CreateSections() method.
Several factors are taken into account, the max length of the chunk (called section here), sentence limit, section overlap, etc.
const int MaxSectionLength = 1_000;
const int SentenceSearchLimit = 100;
const int SectionOverlap = 100;
var sentenceEndings = new[] { '.', '!', '?' };
var wordBreaks = new[] { ',', ';', ':', ' ', '(', ')', '[', ']', '{', '}', '\t', '\n' };
var allText = string.Concat(pageMap.Select(p => p.Text));
var length = allText.Length;
var start = 0;
var end = length;
It also deals with html tables to try and keep the context together. You may want to take a look at that method’s code when creating your own chunking strategy.
Usage of Semantic Kernel
Semantic Kernel is a workflow framework that allows you to interact with Large Language Models (like OpenAI). A lot of the interaction with API’s is abstracted out, leaving your code cleaner than if you write it all from scratch. Semantic kernel also has a prompt template syntax that helps you keep your code clean when working with the prompts. It also provides you with common models that you often need when communicating with chat APIs.
The ReadRetrieveReadChatService constructor sets up the kernel which is then used in the ReplyAsync() method. Take a look at that code if you want to get started with the semantic kernel.
Document loader(s)
There are multiple ways this demo loads files into the blob storage and also the search index. Mentioned earlier the AzureBlobStorageService is used by the UI to upload documents into a storage blob container. Once the blob gets put into storage, there is an Azure Function (the EmbedFunctions project in the source code). This Azure function gets triggered when a new file is added to the container, which then runs the same AzureSearchEmbedService.EmbedPDFBlobAsync() logic used in the PrepareDocs project that is run by AZD in a postprovision hook.
If you need a utility to upload documents, chunk the content, get embeddings from OpenAI and then add to an Azure AI Search index - you should take a look at those two projects.
Other resources
- Blog Post: Transform your business with smart .NET apps powered by Azure and ChatGPT
- MS Build video using the demo: Build Intelligent Apps with .NET and Azure
- Semantic Kernel Documentation
- Document Generative AI: the Power of Azure AI Document Intelligence & Azure OpenAI Service Combined
Other related demos
If you have a comment please message me @haleyjason on twitter/X.